
Many financial services organisations struggle to use customer data effectively for marketing communications. For instance, banks hold rich seams of customer data which could support targeted digital campaigns. However less than half are delivering1. The business impact is significant since consumers are more likely to respond to relevant, personalised offers.
So, what’s behind the problem? It boils down to legacy systems, data silos, and blockers which prevent the connection of multiple sources of data, hindering the generation of actionable insights. Consumer privacy and data regulations compound the issue. The upshot is that it’s hard to leverage customer engagement opportunities presented by social media and other online channels.
This blogpost outlines how Chief Marketing Officers can overcome these issues using a Customer Data Platform (CDP) on Google Cloud.
The Benefits of a Customer Data Platform
CDPs unify disparate online and offline data sources to create a single customer view with multiple data points. They are used to understand customer behaviours, transactions, and products, and to create more personalised marketing campaigns2.
In regulated enterprises, CDPs can support multiple customer-centric use cases. These include enhanced customer understanding and smart customer segmentation. This facilitates effective customer targeting via rule-based or clustering-based segmentation. For instance, marketing teams could segment customers according to their propensity for interest in certain types of credit card:
- Singles with high income (based on high income levels and web traffic related to solo travel) could be targeted with travel credit cards.
- Married savers (based on high savings rates and high web engagement on family and kids related websites) could be targeted with credit cards for everyday family expenses such as groceries.
Sentiment analysis offers another way to target customers effectively. Analysis of social media data could reveal useful insights surrounding attitudes to various financial products such as credit cards, bank accounts, and financial services. Comments, reviews, and ratings could be examined using natural language processing and a sentiment score.
Off the shelf ‘one size fits all’ CDP solutions come with limitations and overheads. These can be avoided by breaking down the requirements and choosing best of breed approaches for capabilities such as:
- Ingestion of a variety of first party source data.
- Processing and enrichment both batch and live source data with third party, public and proprietary data.
- Performing predictive analysis using machine learning to reveal hidden data gems
It’s best to start small with improved ingestion and processing of data to create single customer views across the customer base. The next step might be to incorporate machine learning to tackle more advanced use cases like smart segmentation, consumer signals, and demand sensing to create hyper-personalised experiences. Figure 1 illustrates a digital maturity roadmap for CDP applications.
![Google Cloud’s customer 360 solution for financial services]](https://www.sourcedgroup.com/wp-content/uploads/2024/02/fig_02_digital_maturity_roadmap_bcg_global_RGB.svg)
A Customised CDP on Google Cloud
Working with Google Cloud, Sourced Group (Sourced) an Amdocs company recommends an approach and architecture to facilitate the custom build of a functionally rich CDP. It enables you to scale massively from small beginnings, taking full advantage of Google Cloud’s flexibility and cost optimisation capabilities.
For marketing tooling and campaign management, Google Marketing Platform (GMP) offers unified advertising and analytics helping marketing teams plan, buy, measure, and optimise media and customer experiences. Platform tools include Google Analytics 360, Campaign Manager 360, and Search Ads 360, amongst others.
Figure 2 illustrates Google Cloud’s customer 360 solution which addresses the data, infrastructure, security, and compliance challenges that financial services organisations face3. Customer data is collected, analysed, and visualised before activation for marketing campaigns. Then campaign performance data feeds back into the system to enrich and augment existing data and drive greater value. GMP features in the Activate phase.
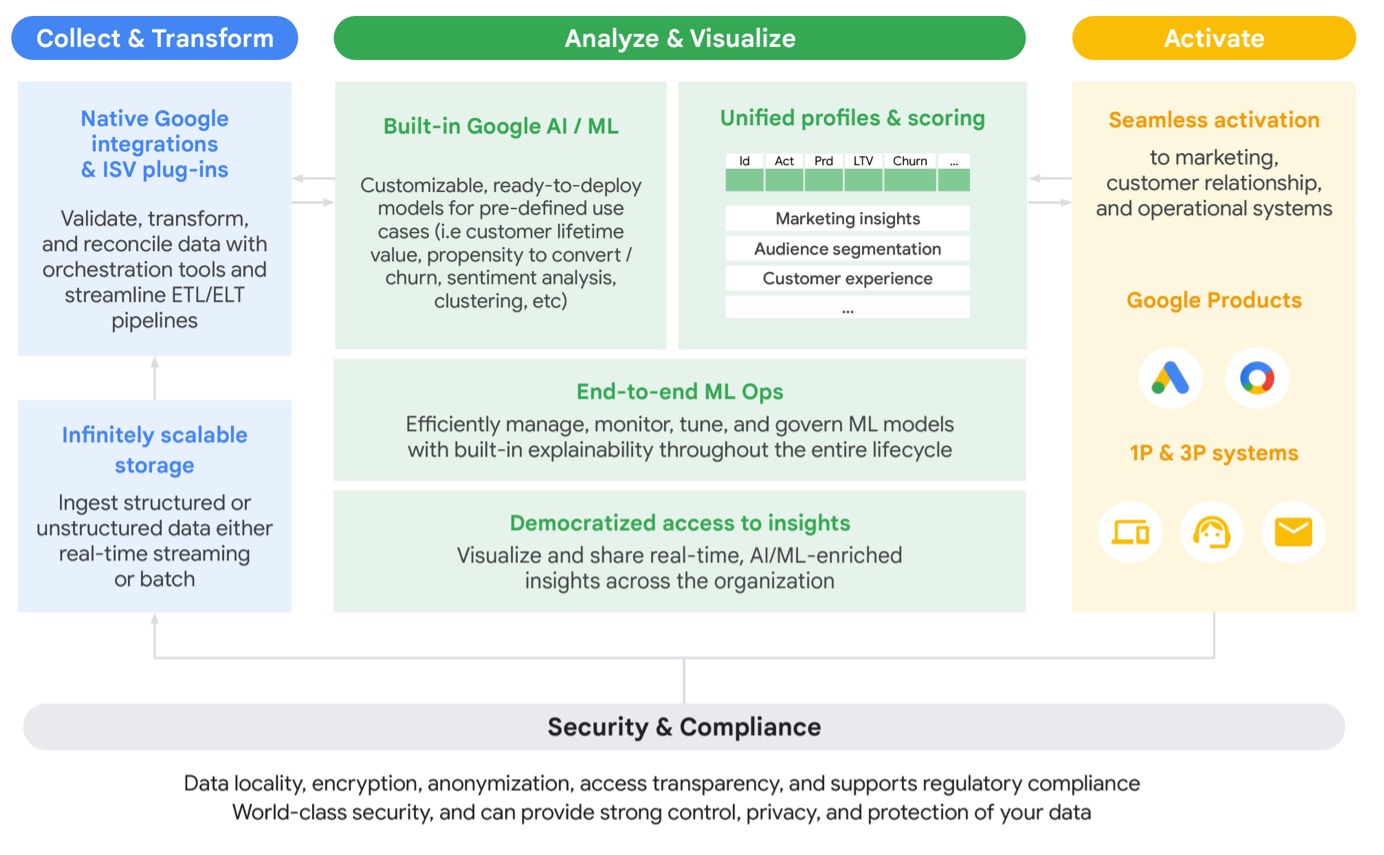
During Collect and Transform, the platform ingests source data. This might come from the organisation’s CRM datasets or customer feedback programs. Data from GMP is progressively added over time too. Additional data might be sourced from public or proprietary datasets. The workflow should be able to handle structured and unstructured datasets along with batch and streaming ingestion.
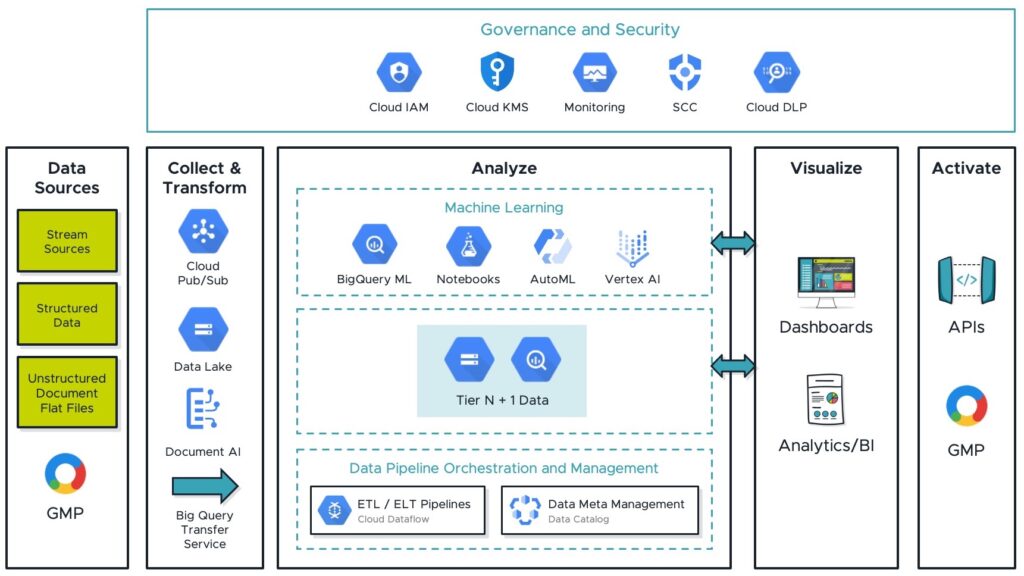
The Analyse and Visualise phase is the heart of the analytics platform. It’s where the organisation brings identified use cases (e.g., Single Customer view, Smart Segmentation) to life, creating data visualisation products such as dashboards and machine learning models. These outputs drive business decisions and strategies, which can feed into GMP as an active campaign. Figure 3 illustrates how a data platform built on Google Cloud might integrate with GMP.
Deep Dive Into Customer 360 Solution Phases
Collect & Transform
Data sources may be structured or unstructured, and might reside in databases, flat files, or message streams. As well as first party data from CRM systems like Salesforce or Microsoft Dynamics, consumer behaviour or campaign response data might be sourced from data management systems like GMP or unstructured documents.
Google Cloud has services that can be utilised to build ingestion pipelines which collect and transform data for storage in data lakes. The example architecture in Figure 3 uses Cloud Pub/Sub to handle streaming data, storage, and the batching of structured data. Introducing Document AI enables structure to be added to unstructured document sources. This managed service can be trained to process documents, eradicating the need for manual processing and data entry.
These ingestion pipelines provide raw data to the data lake, serving as the foundation of Analyse and Visualise. The data lake can be built using cloud storage (Object Storage) complemented with BigQuery (Serverless Data Warehouse).
Analyse and Visualise
As described above, Analyse and Visualise is where we make sense of the data, building use cases and deriving insights to make better business decisions.
Developing curated data assets from the raw data lake requires Extract Transform Load (ETL) or Extract Load Transform (ELT) data pipelines. The Cloud Dataflow managed service can help here, allowing the execution of declarative data pipelines using Apache Beam. This open source service orchestrates jobs which manage the underlying compute required for data processing, ensuring data is sent to its target destination.
Data pipelines create varying levels of data curation for use case requirements. The datasets can be accessed by machine learning services to develop and publish machine learning models. Alternatively, they can be extracted and published on dashboards using Looker or offerings such as Microsoft Power BI and Tableau.
To stitch all this together, Google provides a managed data catalogue (Dataplex). This key component allows the organisation to discover and manage all data assets residing on the platform. Technical and Business metadata is stored within the catalogue, which serves as a key foundation, establishing a robust data governance framework.
Activate
Finally, activation occurs with insights and intelligence gathered from the data used to generate actionable outcomes and campaigns. Data gathered using GMP is then fed back into the platform, allowing the organisation to build quicker iterations and releases which adapt to real-time feedback, thereby advancing data maturity and enabling the organisation to tackle advanced use cases.
Addressing the Security Needs of Regulated Enterprises
According to a McKinsey survey published in August 2022, only 13 percent of financial services companies had half or more of their IT footprint in the cloud4.
In our experience, concerns surrounding data protection in cloud environments are the biggest barrier to regulated enterprises’ mass cloud adoption. Financial services organisations in particular fear the reputational damage that could result from data breach incidents. Shared responsibility models put the onus on the organisation to deploy cloud resources securely and protect the data that resides there. Consequently, some organisations introduce overzealous controls which hinder cloud adoption and restrict it to side projects with no meaningful workloads. To transform the way lines of business make data-driven decisions via cloud-based CDPs, these data security concerns must be tackled head-on.
A Platform-led Approach to Cloud
There are two main approaches to cloud adoption: workloads and platforms.
With the workload approach business units develop bespoke cloud deployments and collaboration with the central IT team is minimal. This delivers short term velocity, but it cannot scale. Each new workload adds overhead and burden to central IT who hold responsibility for compliance and controls. Lengthy review and approval processes are common, reducing developer efficiency and negating the benefits of cloud environments.
To overcome this, we advocate a platform approach to cloud adoption. Controls, operational requirements, and guardrails are baked into a cloud platform which business units leverage to manage their application landscape.
This ‘shift-left’ approach democratises cloud consumption. Rather than executing infrastructure deployments, the central IT team maintains the platform. The velocity of deployments increases, promoting an environment of experimentation and reduced time to market, while maintaining compliance and adherence to regulatory directives and controls.
The cloud platform sets the foundation for the data platform, which adopts the same approach and inherits applicable controls for resources associated with data workloads.
For details on our approach to cloud platforms for GCP, please review our whitepaper.
Read WhitepaperSecurity Controls on Cloud Platforms
So, how are controls enabled via a platform? Holistic approaches work best, covering the underlying infrastructure and the protection of data assets.
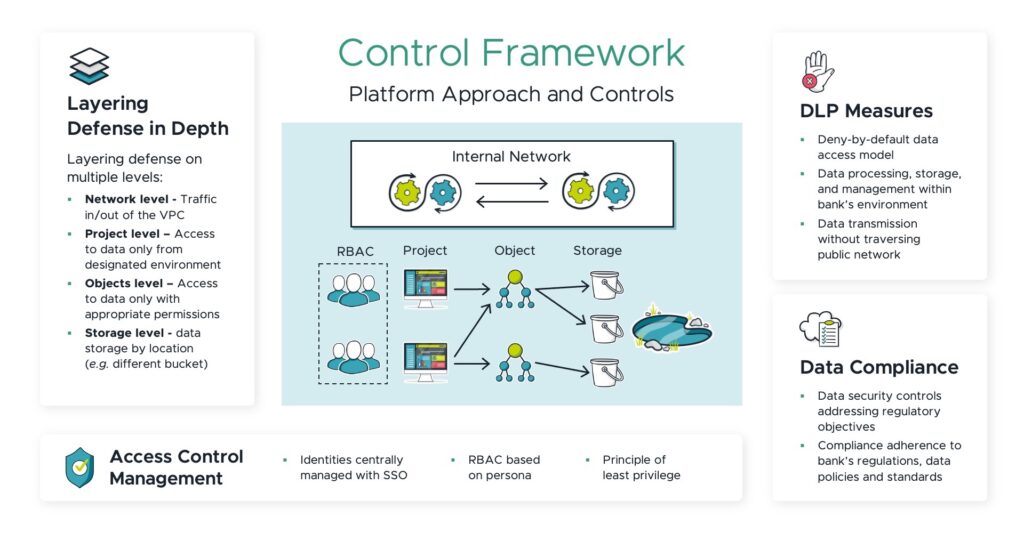
Primary controls align with regulatory, internal, and industry best practice directives. These translate to secondary controls which are implemented in the platform to achieve the desired compliance posture. Figure 4 illustrates a platform-based control framework, and we expand on key elements below.
Securing Cloud Infrastructure
A cloud infrastructure encompasses both platform level and workload level resources. Controls should be implemented at all levels to achieve security and defence in depth.
Platform level resources include areas such as the network, access control, or the project (which is a virtual container of cloud resources). Workload level resources relevant to data would include storage devices like Google Cloud Storage (GCS), BigQuery or ETL pipelines managed by Dataflow.
Table 1 outlines an example of control implementation layers using GCS. It includes platform and workload level controls that should be enforced with any deployment of a cloud resource. We recommend enforcing these controls within infrastructure-as- code as repeatable patterns used for every deployment.
| Primary Control Objective | Secondary Controls | Domain |
|---|---|---|
| Mitigate unauthorised access to data objects outside of the organisation’s trust boundaries | Contain restricted storage assets within a defined VPC Service Perimeter | Platform |
| Apply an organisational constraint to restrict access to defined internal domains | Platform | |
| GCS buckets deployed should be attached with IAM to allow access to authorised Principals within the Project Resource | Workload |
Table 1: Control implementation layers
Governing and Securing Data
Let’s take a closer look at data governance, followed by access and security measures (which may be proactive or reactive in nature).
Data Governance
It is important that financial institutions have a dedicated program to help govern the controls framework. Usually, data governance programs comprise a few main components grouped under broad categories of People, Process, and Technology. Table 2 provides a non-exhaustive list of components5.
| Theme | Component |
|---|---|
| People |
|
| Process |
|
| Technology |
|
Table 2: Example components of a data governance program
People Components
1. Data Governance Training and Education
Employee(s) involved in the data governance program should be trained in key concepts to ensure the success of the program.
2. Data Governance Roles and Responsibilities
The data governance program should have clearly defined roles such as Data Owners, Data Stewards, and Data Consumers. Employee(s) assigned to each role should understand key responsibilities and the decision-making authority they possess. Access control to data products via role-based access control (RBAC) would require the right data owners to assign the right people access to the right data.
Process Components
1. Data Governance Policies and Procedures
These policies and procedures should provide guidelines for data management, data quality, data privacy, and data security. They should be clearly documented and circulated across the company.
2. Data Stewardship and Change Management’
In the case of new or modified datasets, changes in access control should be managed by the data stewards or owners. For example, they would have to ensure that data users are kept informed of any changes in the definition of various fields in the dataset, so they can handle the changes accordingly in any downstream data pipelines or dashboards.
Technology Components
1. Data Quality Management
Regulated enterprises should use processes or tools to monitor, measure, and improve data quality. A data quality tool could have features to define data quality metrics, continually monitor these metrics, and automatically handle various data quality edge cases.
On Google Cloud, Dataplex would be a potential tool for managing data quality. It has various in-built features to perform data profiling and provide data quality recommendations, as well as monitoring data quality scores. This would provide data owners and data consumers with confidence in the reliability of downstream data products (e.g. dashboards, customer segmentation models).
2. Data Catalogue and Metadata Management
A data catalogue should be used to document and manage data assets and their metadata. At an organisational level, this provides visibility and confidence in the data platform and its regulating data products, enabling data discovery, lineage tracking, and a better understanding of data relationships and dependencies.
Use of Dataplex is possible here too. With features such as automatic data discovery, metadata harvesting, and a business glossary, it can turn raw data from silos into governed unified data products ready for analysis.
3. Data Security and Privacy
This would include proactive or reactive measures to protect sensitive or personally identifiable information (PII). Methods such as data access control and tokenisation are discussed in the subsequent sections.
Data Access Control (proactive)
The cloud platform must have a centralised access control point to the data platform. This can be achieved with an RBAC framework implemented on Google Cloud, syncing existing corporate Active Directory to Cloud Identity. Platform administrators can subsequently exercise granular access to data workspaces and resources using Cloud IAM.
Data Encryption, Tokenisation and Masking (proactive)
Data is encrypted at rest and in transit by default when a data platform is built on Google Cloud.
- Encryption at rest protects customer data from system compromise or data exfiltration during storage, typically within GCS in a data platform.
- Encryption in transit protects data traversing over the internet or within private networks. It is encrypted before transmission, then decrypted on arrival as well as undergoing verification to check it has not been modified.
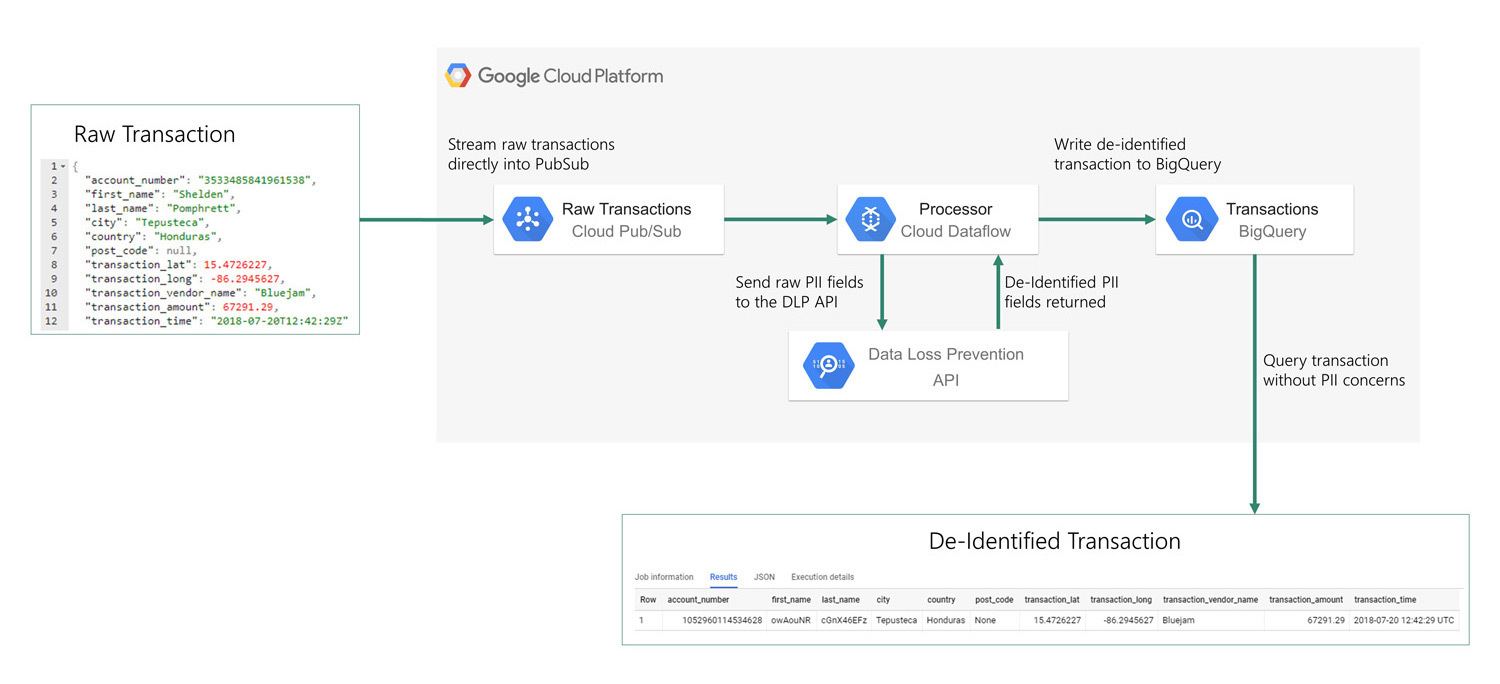
We also recommend masking or tokenisation for sensitive or PII data as appropriate. In Google Cloud this might involve use of Data Loss Prevention (DLP) within Cloud Dataflow pipelines. Figure 5 outlines a reference architecture for this implementation, demonstrating how Google Cloud might be used to handle data in a secure manner in a regulated enterprise. Raw transaction data is ingested, PII data is located, and these fields are de-identified. Then the transactions are written to a new destination for analytics purposes. Democratising data for analysis, whilst adhering to regulatory obligations, can be challenging for financial services organisations. However, it can be greatly simplified with DLP API (the source code for this example is available in the footnotes below6).
Scanning for PII Data (reactive)
A robust and proactive Data Governance framework provides a high level of security. However, despite best efforts there will be mistakes and unmasked PII data might slip through the cracks. As such, a secondary level of reactive control scanning should be enforced for PII or sensitive data to ensure it is sufficiently protected. On Google Cloud, a managed service such as DLP could scan selected data assets.
Customer Data is the Key to Commercial Success
To remain competitive, banks and other financial services organisations need to get more from their customer data. Those which build towards high digital maturity can harness data more effectively, enabling next-level customer experiences through tools such as machine learning, driving highly personalised recommendations (micro-segmentation) for financial products and services. They can also use consumer signals to improve demand forecasting, optimise marketing spend and accelerate innovation with faster feedback loops using consumer data to measure campaign success7.
Achieving this vision requires an effective data platform underpinned with robust security and governance. Our suggested design for a data platform on Google Cloud ticks all the boxes.
- https://www.insiderintelligence.com/content/survey-customers-banks-lackluster-grades-on-their-personalization ↩︎
- https://www.hull.io/blog/customer-data-platform.html ↩︎
- https://services.google.com/fh/files/misc/wp_lead_the_way_in_customer_focused_financial_services_with_analytics_and_ai.pdf ↩︎
- https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/three-big-moves-that-can-decide-a-financial-institutions-future-in-the-cloud ↩︎
- https://atlan.com/data-governance-key-components/ ↩︎
- https://github.com/sourced/dataflow-transactions-demo ↩︎
- https://www.bcg.com/publications/2021/the-fast-track-to-digital-marketing-maturity ↩︎

Somnath (Som) is a Principal Consultant at Sourced with over 4 years of cloud consulting experience in regulated financial institutions. In his time at Sourced his areas of focus have been in developing cloud platforms, and being a trusted advisor in cloud security and solution architecture.

Celeste has over 6 years of experience in data science and analytics, and has worked with some of the largest consumer datasets in the region. She has worked closely with product and business stakeholders in various domains including financial services (FSI), Telco and FMCG, with deep knowledge of customer experience optimisation across verticals.


