
Event Storming is a workshop-based approach to migrating a monolithic application to a microservices architecture. It follows a series of steps to assess the monolith, discover events, and identify actors who use the system. The final step of grouping these insights will help to inform an effective event-driven microservices architecture.
For an introduction to Serverless microservices and an explanation of the differences between Monolithic and Microservice architecture, please see this article.
The rise of Microservices has brought about both challenges and opportunities. The flexibility in scaling individual services based on demand, code reusability, fault isolation, and cost optimisation are just a few of the more common benefits. While adopting a Microservices design for new applications can be achieved relatively quickly with an experienced application team, redesigning an existing monolithic application into Microservices while satisfying the project’s business requirements can be challenging.
When converting an existing application, there is a risk that the application team may miss functionality or integrations built into the project over time . When users use the new version of the application, the missing capabilities are jarring and affect the user experience. In contrast, a new application means the team to start with a blank slate with no comparisons being made to existing solutions.
Microservices also enable developers to work on different parts of the project independently, in different repositories and with less oversight. While this can speed up timelines and offer developers more freedom, it can also result in consistency challenges if clear standards and best practices are agreed at the start. Conversely, with a monolithic application everyone works on the same repository and there are many dependencies between different parts of the application. , As such, the application teams have to work more closely together, are frequently interacting with each other’s code, and so, can more easily review and provide feedback for any inconsistencies.
Common issues that application teams face when redesigning a Monolith include:
- Broken integrations between Microservices
- Duplicated services across Microservices
- Microservices that are incomplete
- Ending up with a distributed Monolith
A typical Monolithic application would have undergone multiple code iterations with different developers that come and go during the extended application life cycle. Often having siloed teams handling the various aspects of the project such as security, networking, operations as well as development. Monolithic architectures frequently comprise many isolated components within a system and it is uncommon that any one individual knows everything.
Understanding a Monolith requires deconstructing it into its smallest possible units and then piecing them back together. The deconstruction lays out all aspects of the Monolith and creates a consistent understanding across the application teams. It also provides a birds-eye view of the entire process, allowing application teams to easily identify the purpose and relationship between the different pieces of a Monolith. This visibility minimises the likelihood of missing functionalities or integrations when designing your Microservices and determining their scope.
Event Storming
Event Storming is an effective approach to deconstructing your Monolith and establishing a clear and consistent approach to developing a new event-driven microservices version. It was introduced by Alberto Brandolini in 2013 when he wrote the first article about Event Storming. Event Storming is a workshop-based approach to generate conversations and create visibility into complex business domains. It aims to deconstruct a business process by identifying the events, processes, people, policies, and systems within the process.
Since the inception of Event Storming, organisations have created many variations, for instance, IBM developed an extended version and coined it Insights Storming, with an additional step to identify possible future events. VMWare Tanzu, on the other hand, created a simplified version by taking away components such as the policies and artifacts from the process. The key takeaway here is that there is no fixed style to Event Storming. The focus of Event Storming is to facilitate knowledge sharing, and organisations may adapt it as needed based on their business and team requirements. In this article, we will be looking at a general approach to Event Storming that works for most teams.
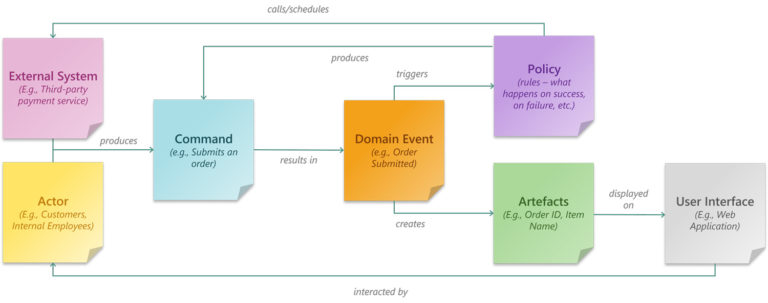
Before we dive deeper, let’s cover the core components and terminologies often used in Event Storming exercises. Each component used in Event Storming is represented by an arbitrary but uniquely coloured sticky note. The following component-color combinations can be considered a legend for this article.
| Components | Description |
 Domain Events (orange) | An action that has occurred, usually a verb described in the past tense, for example:
|
 Commands (blue) | Identifies the trigger for each of the events, for example:
|
 Actors (yellow) | The users that give a command or are being notified of something by a process. Try and be specific, for example:
|
 Systems (pink) | The systems and third-party services within the process that interact with your application. These systems can give a command or be notified by a process, for example:
|
 Policies (purple) | A set of rules that define the appropriate next steps to take after an event. For example:
|
 Artefacs (green) | An output of interest generated by the events |
| Timeline | A sequential flow of the events through the business process |
Aggregate (green gradient bars) | A collection of related events and commands that can be grouped into a broad categorisation (Usually business objects such as Order, Customer, Inventory) |
| Boundaries | Bounded context groups separate business domains from one another. They can be an indication of individual Microservices. |
With these concepts and terminologies in mind, we can now dive deeper into how Event Storming can turn a monolithic legacy application into a modern Microservices one.
Preparation
Two key requirements need to be address prior to the workshop.
First, you need to identify the right people that are to be invited to the workshop. You will need an experienced facilitator to engage the participants and help to drive the discussion and manage the time appropriately. A workshop typically involves six to eight stakeholders, including members of the application team, the solution architect, project manager, product owner and specialists such as security, compliance or legal. The attendees are expected to have sufficient expertise to ask the right questions and answer questions regarding their domain.
Next, you will need the space and resources. Traditionally, a classroom-like setting is used for Event Storming exercises where you have enough room for people to discuss and paste sticky notes. Besides pens or markers, sticky notes are a crucial element in your workshop and help visualise the flow of your process. Try to have a variety of colours as differentiating the different components of your diagram will make it easier to understand them. You can consider sticky notes with different shapes or patterns rather than different colours for a more inclusive option. If you follow this guide, seven distinct sticky notes and a small sticker to flag sticky notes that need a follow-up are recommended. Note that the colours we have used here for each item are arbitrary; you can adjust based on the sticky note styles that you can procure.
We can pivot to an online setting when meeting in person is not feasible due to space constraints or the COVID-19 pandemic. Useful tools, such as Miro and OneNote, provide virtually unlimited digital space for jotting down notes. The facilitator will need to be comfortable leveraging such a platform to conduct the session, and they need to mitigate the additional challenges of having an online workshop. Zoom fatigue, having a single conversation, distractions, lack of empathy and having proper IT resources are just some of the challenges that need to be addressed to have a successful session.
Step 1: Identify the Events
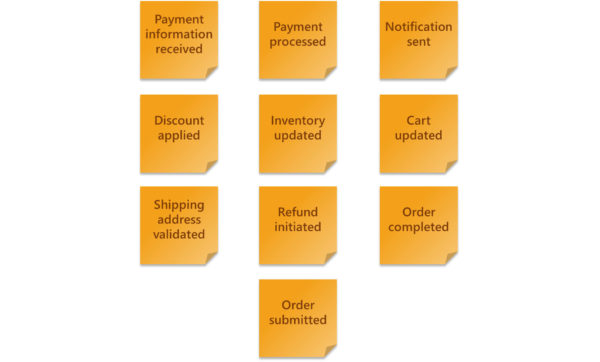
Each item in this step identifies a business event within your application. The focus is to capture as many Domain Events as possible and avoid over-analysing them. Domain Events are written on an orange post-it as a verb (action) in the past tense. For instance:
- Item added to cart
- Payment confirmed
- Order submitted
- Order shipped
- Order received
Participants in this step can start independently to generate as many Domain Events as they can think of. This part can be a bit chaotic, as everyone contributes according to their understanding of the application. Do not worry about duplicate Domain Events that may be worded in different ways, as we will be addressing that in the next step.
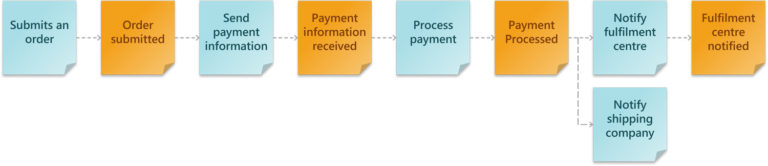
Step 2: Sequence the Domain Events
When the participants have contributed all of their Domain Events, we gather everyone to organise the Domain Events and create sequences.
The Domain Events are sorted from left to right, and we remove or merge duplicated Domain Events. For alternate or parallel Domain Events, we can separate and organise them using swim lanes. While organising the Domain Events into a sequence, we will often identify missing Domain Events – feel free to add them to complete the sequence.
The resulting timeline should give everyone an overview of the entire application and the integration between different components.

Step 3: Identify the Commands
Once we piece the different Domain Events together, we can then identify the source.
Commands are the actions that trigger an Event and can be initiated either by an Actor or a System. Commands are added on blue post-its and written as verbs in the present tense. When designing your Microservice, Commands often translate into an API implementation or Microservice trigger.
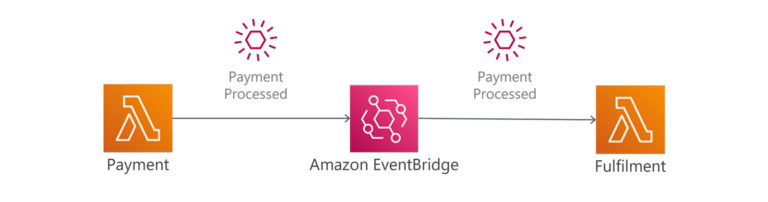
In AWS, API implementations are typically implemented with the AWS API Gateway service, with integration to Lambda microservices processing and responding to requests. Microservice triggers are handled through integration services such as AWS EventBridge. The producer of the events can either be an AWS service, such as when a new file is uploaded into S3, or a custom event, such as when your microservice completes a transaction.
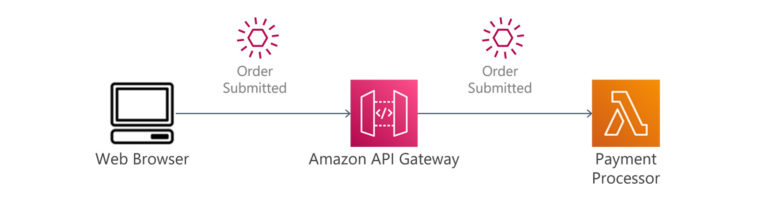
Step 4: Identify the Actors and Systems
Actors are the people that interact with your application. For example, they could be internal employees issuing commands or external customers clicking a button on your webpage. Actors are represented on a yellow post-it note.
Systems are other entities such as other components in the monolith or third-party applications that interface with your application. Systems create Commands based on pre-defined scripts such as a scheduled job or when certain conditions are met in resource or log monitoring.
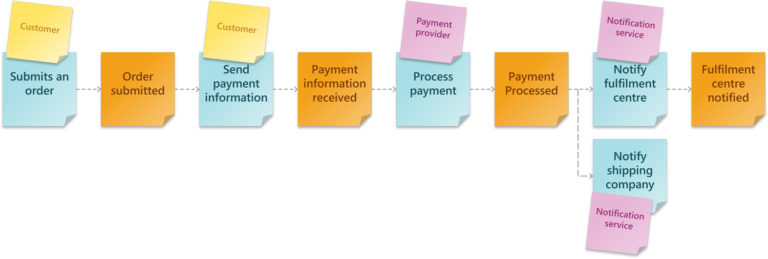
Step 5: Identify the Policies
Policies are applied after a Domain Event has occurred to help determine the appropriate next Domain Event in the sequence based on defined rules. Policies, noted on purple sticky notes, include the execution condition (scheduled, on success, on failure, etc.) and define your application’s business response to a given situation.
Once we have defined the policies, there are several places where we can incorporate them into your application design.
For example, we can create a model schema in API Gateway, which does validation such as looking for required fields and value types. For more complex validation, we can have a custom microservice, such as checking on inventory availability.
We can also use Amazon EventBridge, to decide how we want to route each event to one or more microservices. For example, a successful payment event will be routed to the inventory microservice, whereas a failed payment event will be routed to the notification service.
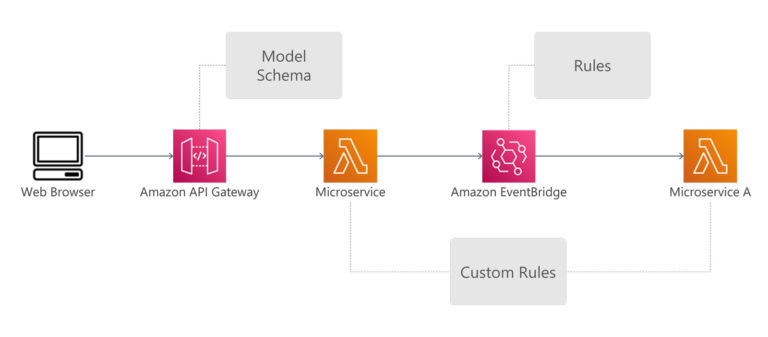
Step 6: Identify the Artefacts/Schemas
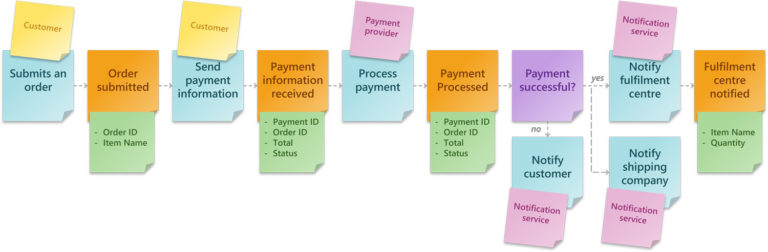
Once we have identified the input parameters, we can determine the Artefacts or Schemas generated from the Domain Event. Knowing the Schema helps to identify sensitive data such as Personal Identifiable Information (PII) so that we can implement additional safeguards to protect it. The resulting information will later help define the database schema for the application, identify common attributes used between different events, and help determine the appropriate type of database to use. In the case of Artefacts, it will help identify the appropriate storage service and features that may be required, such as compression, encryption, or versioning. Artefacts and Schemas are added on green sticky notes.
With purpose-built databases, organisations can derive more value from their data. Unlike relational databases, these databases are purposefully built with advanced analytical capabilities and better performance to cater for specific use cases such as social networking, recommendation engines and clickstream analysis.
Some examples of purpose-built databases in AWS are:
- Amazon QLDB, a ledger database for data that requires a high level of integrity, such as transaction records.
- Amazon Timestream, a time-series database where the order of events are important, like clickstreams or logs.
Amazon Neptune, a graph database for storing relationship, ideal for use cases such as a recommendation engine or a social network.

Step 7: Aggregate the Domain Events
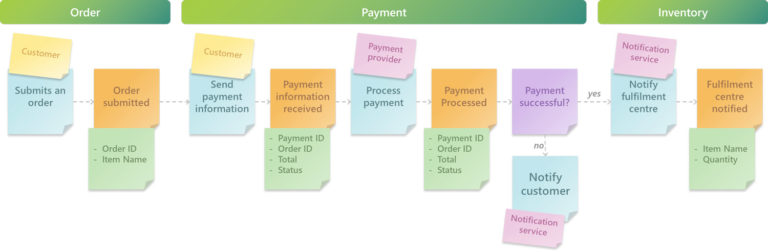
Aggregates are typically represented as nouns, and they are your business entities, typically stored in a database. To put it simply, they are the things that your Commands are acting on and what your Domain Events are creating, reading, writing, and deleting. Some examples of Aggregates using our example below are order, payment, product.
Expanding on our previous example, we have an Order Completion context that updates the order’s record and the customer’s loyalty programme points when an order is completed.
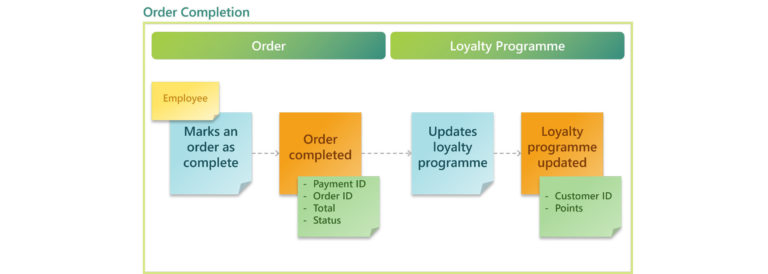
In this example, we have two Aggregates within the same Bounded Context. Instead of designing just a single Microservice within a bounded context, we will have two; one for updating the order status and another for updating the loyalty programme.
Putting it all together
When we have finished the Event Storming process, we collate the output from each step to design our Microservices and the broader application architecture. To recall, here are our generated and how they might correspond to Microservices.
- Bounded Contexts > Microservices
- Policies > Business Logics
- Commands > API Implementation or Trigger
- Aggregates > Database/Storage
- Schema > Database schema
- Artefacts > Storage service and, potentially, a file structure
- Systems > Integrations with other services (internal or external)
When we turn our ‘order’ Boundary into architecture, it may look something like this:
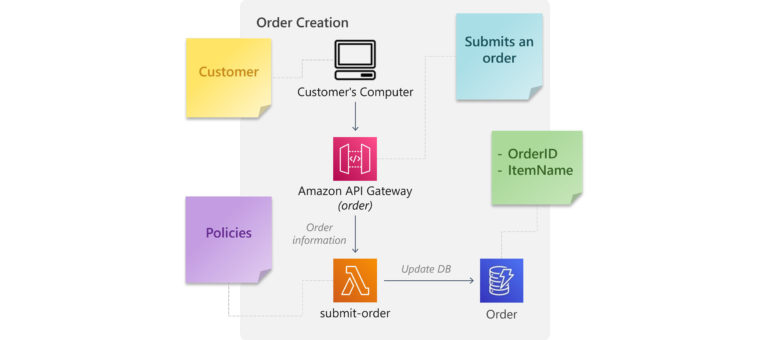
The Event is “Order Submitted”, the Actor is our customer, and the Command is the customer submitting an order from the e-commerce UI to the API Gateway Service.
In API Gateway, we implement a Policy by using the model feature to validate the user-submitted values. An attached Web Application Firewall or Cognito authentication can also be considered a Policy. A negative output from either of these will result in an error response to the customer; success means the order is sent to the submit-order microservice. The microservice might have additional Policies that cannot be handled in API Gateway.
Once the microservice has accepted the order, a Schema is created from the provided parameters, which will be inserted into the order database.
Lastly, we might consider including SQS, SNS or the event of creating a new record in our order database to trigger the next step in the order sequence.
Conclusion
When conducting your Event Storming exercise, organisations should remember that the focus is on knowledge sharing, and they should customise the process to best suit their organisation’s and project’s needs. For the developers, if a Microservice seems too large after scoping it based on an Event Storming Boundary, consider splitting the Boundary into smaller ones. Another Event Storming exercise with a smaller group can be organised to tighten up the scope of Microservices and ensure they are independent, event-driven, and lightweight.
Reference
Event Storming: The smartest approach to collaboration beyond silo boundaries
IBM: Event Storming
VMware: Event Storming

Thomas is a Lead Consultant at Sourced with over 18 years of experience in delivering digital products. He gained a passion for evangelising Serverless architecture through his enthusiasm for cloud and entry into the AWS Ambassador programme.

KangZheng is an up-and-coming AWS Cloud Engineer with two years of professional experience in architecting and implementing cloud solutions. He enjoys researching the latest technology trends and applying them to client projects.


