
The pros and cons of Ansible and Puppet, from a lead DevOps engineer who’s worked extensively with both tools.
I have realised that people still struggle to find differences between Ansible and Puppet. As more of a Puppet person myself, when I had to switch entirely from using Puppet to Ansible within my role, I found that sometimes I started to favour Ansible over Puppet.
In this blog I’ll explain the pros and cons for each with some technical examples.
In Short…the Differences
In very, very, short, there are some differences between Ansible and Puppet.
I would normally classify both as different use cases (more about this below) but in general, before you start, you do need to know what Puppet and Ansible are. Puppet is more of a configuration management tool, whereas Ansible is more of a provisioning, configuration and deployment tool. Despite the fact Puppet now can provision infrastructure, I would really think hard about whether I would consider Puppet for that task. Anyway… let’s start.
Ansible is Simple! (They Said)
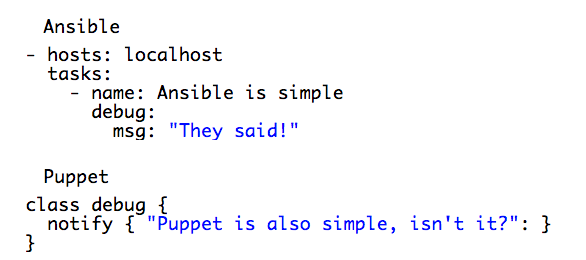
As a side note, Ansible uses YAML language, whereas Puppet has its own declarative language. If you make a mistake in Puppet, it can be easily highlighted and in many cases Puppet Lint or Puppet Run will just fail.
In Ansible, tasks are executed in specific order, if you have syntax errors in plays or roles, they tend to fail once you hit them, not before you execute the entire play. Playbooks waiting for a feedback can take a long time. In this case I actually favour Puppet because it won’t compile a catalog if there are issues with the syntax.
Some may say “Okay but Puppet also uses YAML”… yes it does for hiera and at the same time if you make YAML errors in Puppet you may hit similar issues with Ansible.
To illustrate what I’m thinking of have a look at the data structure below:

YAML lint won’t drop any errors or warnings but in general the above breaks the entire structure. Have a look at this play:

If we lint it and run it:
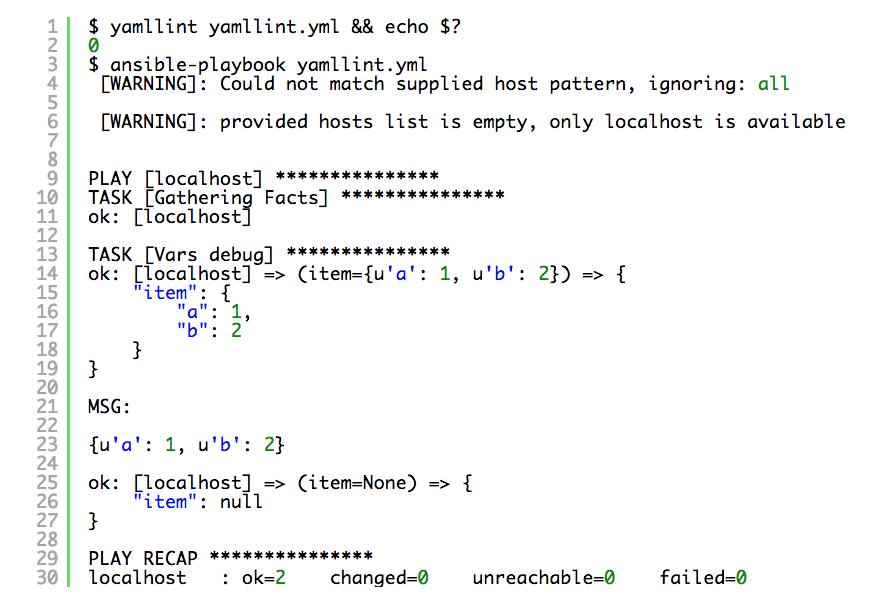
As you can see in the example above, the first item has been found with correct key value pair, the second item was just null. This is because of the wrong indentation which completely changed your data structure. You may say “Yes but that’s pretty obvious!”. Well, it is and it’s not, especially for beginners and this is quite a common mistake that people make (including myself). I also experienced much more serious YAML hierarchy errors in the bigger plays because of this type of indentation mistake, which haven’t been picked up by YAML lint at all. People who work with YAML a lot know this is not the easiest language to debug.
Ansible Needs to Know What to Run Where…
…as well as Puppet. Ansible is strictly tied into an inventory which you have to manage as a flat file, (or) dynamic inventories or smart inventories. If you want to run a task against the server which is not in your inventory, Ansible simply won’t run anything. Puppet agent checks in with the master and the master manages “the inventory”, but you need to declare nodes (servers) configuration as well, unless you use default node declaration which will then apply for all the hosts. Puppet also requires nodes certificates to be signed (manually) on the master. This gives you some confidence that the code won’t run or be executed against the servers that are not trusted (or configured). You can use autosign.conf if you want your master to sign certificates automatically (can be limited to certain hostnames or wildcards).
Don’t Reinvent the Wheel…
Modules. Both solutions come with a great bunch of modules and/or roles already written by people and are kept in certain “repositories”. For Puppet you should look at Puppet Forge, and Ansible Galaxy for Ansible.
When I have to write something I always go and check these resources to simply save some time and hassle. If I can find a module which is doing something for me that I want, I pick it up (instead of writing it on my own because there is a big chance someone has already done that better than me anyway).
Based on my experience I would say Puppet is an unbeaten champion when it comes to the module choice and quality. Puppet Forge is a huge module library and what actually helps is that PuppetLabs manages some of the modules themselves. Modules which are written in accordance to some PuppetLabs best practices can be rewarded by the Puppet team with Supported or Approved marks/grades. This really helps in making your decision on which
module to use, simply because you want the best ones which are being actively developed every day. You also want modules that are tested and proven to work.
For me, this is the main reason why Ansible lost the battle. I tried some modules recently from Ansible Galaxy and two out of the three I used required some manual changes and modifications to do what I wanted. I don’t want to name and shame here but I was using some collected and zabbix agent modules.
But Puppet Needs Extra Components!
True. A common argument I hear against Puppet is the infrastructure needed to support your automation processes. If you want to fully utilise Puppet… it needs infrastructure. If you want an access to the node’s facts, reports, etc you need puppet master(s), puppet db(s). In many cases people link this argument with an overhead which Puppet brings in. I cannot answer which is better, as in my opinion Puppet and Ansible serve slightly different purposes but are very similar to each other.
Another argument against Puppet is that to run it you need X puppet. In fact, to run ansible-playbook, you need Ansible. The difference is that ansible-playbook can be run from centralised places, whereas Puppet needs an agent to run on each node. Unless you run masterless configuration and you execute your puppet manifests locally on the box, then it also requires puppet to be installed on that server + source code of your all modules and manifests.
In short, Puppet will always require an extra component/package to be installed on the destination server to make it all work, regardless of whether you go masterless or not.
Ansible can Deploy and Configure Stuff at the Same Time…
Yes. This is true. You can use built-in Ansible modules to provision your infrastructure by plugging in directly to the infrastructure providers (AWS, VMWare, Azure, etc). You can describe your infrastructure as a code, and configure it on a run as well.
As long as Puppet has similar modules and abilities (for example AWS) I would really feel uncomfortable running Puppet code to deploy AWS instances… but this is entirely my personal opinion. I would more than likely use Terraform or Ansible instead for that task.
Provisioning Complex Infrastructure and Configurations…
As I mentioned above Ansible (or Terraform) would be my choice of tool for provisioning infrastructure. If you have an environment which needs to be built in certain order you can design your play to wait for certain components to be present, or work in your infrastructure before you start configuring bits and pieces. I’m not sure if you can do that with Puppet. I personally have never done it simply because of the reasons mentioned above.
Complex configurations can be equally hard or equally simple in Ansible as well as in Puppet. If complexity is the case you would probably have to write something on your own, with your own set of templates or flat files, so the chosen tool here can be a personal preference.
Task Scheduling…
Sometimes you want to run your tasks every so often. Puppet agent runs every 30 minutes by default, making sure the checked in node (server) is in the desired (described) state. Ansible doesn’t have that mechanism so if you want a scheduler you need to look at Ansible Tower which has recently become open source. Puppet just has it all by default. So, when we talked about the extra infrastructure above and an overhead… if you need some Ansible fireworks, you should look at Ansible Tower (or AWX).
Puppet is a Devil’s Tool Because…
“It doesn’t allow me to make manual changes on the servers.”
– True. When Puppet agent runs it will revert all your changes if they differ from what is described in Puppet manifests. But this is exactly what you want, is it not?
“Not really, I want to make manual changes so I think I will stop or disable Puppet agent.”
– You can yes, but this is definitely not something you want.
For some people, the above sounds familiar. The main purpose of scheduled runs is to make sure code reflects the current configuration on the destination systems and enforces that configuration. I think a lot of people are guilty here as everyone (including myself) has been in a situation where you need to turn Puppet agent off to test or change (and then test) something on the live system. In many cases this behaviour is enforced by the test infrastructure which doesn’t exist. Live is not ideal, but unfortunately in some cases you have to do that.
Different Codebase per Environment…
Puppet has one of the best tools I have ever seen and used and it’s called r10k. I absolutely loved it when (first of all) I worked out how to use it! In short, r10k is a tool to manage your modules depending on the branches or your specific environment configurations.
It builds your entire Puppet module ‘code base’ based on what is described in Puppetfile for that specific environment. This means you won’t have any accidental modules within your module inventory and each module is kept in separate git rep. Full win! This makes module management and development much easier as well as testing your changes. You can also refer different modules from different branches, versions, commit points, etc to your production or QA environment (for future promotion).
For example, let’s say this is my Puppetfile in production:
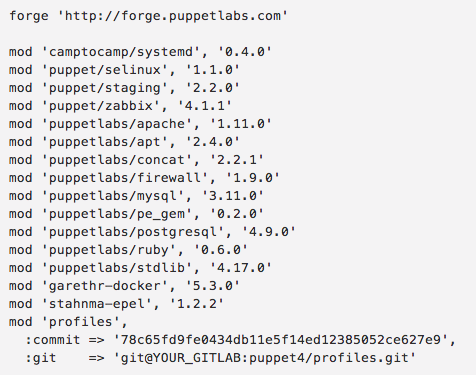
When you run r10k deploy environment production -p assuming my above Puppetfile is in production branch in git, it will download all the modules listed from Puppet Forge and the profiles module from my personal GitLab server, but with the certain commit number. So if I want to test my profiles on the QA environment assuming I have QA branch in my local GitLab where I make all my changes I just do this:
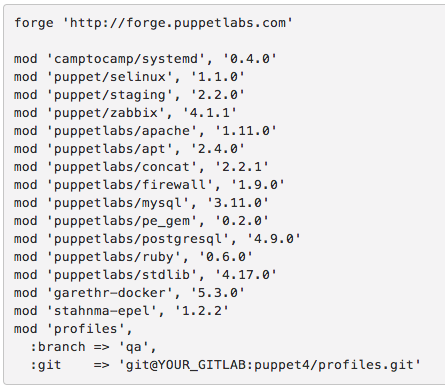
After running r10k and your puppet agent pointed to the qa branch… you will test these changes. r10k is definitely worth a separate article.
I cannot imagine the way I could do similar things in Ansible.
Summary
To summarise this article, both offerings are definitely worth considering. If you are a storage or network engineer then I think you should not look any further and go straight for Ansible. I think Ansible wins a lot in terms of the provisioning side of things if your deployment requires ordering or some special tasks which have to be well planned and rely on each other. I also think Ansible is good for short-lived environments as it takes the headache away of managing Puppet node SSL certificates etc. It’s not a big deal though and I think Puppet can be as good as Ansible here.
Puppet is definitely more mature and in terms of support, I believe it has more to offer. Ansible can be simple to start, but when you get into more complex tasks you may find it very difficult to manage them. Ansible without Tower is not really ‘idiot proof’ (or safe) as it simply allows you to run playbooks on your entire inventory. Imagine a situation where you declare a new root password in your Ansible Vault, run your play, and halfway through you realise that password is something that you don’t know because you mixed up SHA256 hash. If you use password authentication to access your servers (which isn’t ideal anyway as you should use SSH key authentication only), you have just lost an access to some of your infrastructure irreversibly.
If you use key authentication and you have to change the key for your account (to the wrong one), you again lost an access irreversibly to (part of) your infrastructure. With Puppet that situation can be reverted as agent runs every so often, so you can correct your mistake in your code, deploy it to Puppet master and wait for another Puppet agent run.
In my opinion, Puppet has more modules which are better-written and just work. It is a more enterprise-ready solution. Unlike tasks scheduling in Ansible without Tower which leaves you with only a few options.


