
Introduction
In our previous blog post, we learned about Personally Identifiable Information (PII), and the additional regulatory requirements that it carries. We covered three common requirements of PII regulation:
- Tracking Access; which talks about being able to audit who is accessing sensitive data, when they access it and where they access it.
- Protecting Data; which talks about how we secure data in transit and in storage.
- Retaining Data; which addresses managing data life cycles i.e. how long data should be kept for.
In this second instalment of our series, we will look at how Serverless technologies can assist to easily and confidently address these three common regulatory requirements.
Tracking Access
To answer how we address this requirement in the cloud, we will look at the Principle of Least Privilege, a common security strategy and one of the most powerful tools in Serverless security. Then, we will look at some of the logging and monitoring capabilities in the cloud and how we can expand on those to be more proactive.
Access Control Following the Principle of Least Privilege
We defined the principle of least privilege, or PoLP, in the previous blog post; it is a common security strategy that is not unique to Serverless, but is considerably more powerful in this architecture.
With a server-based approach to PoLP, the entire application, and indeed the entire server, will have access to everything that each function in the application needs access to, such as databases and shared storage. If any part of the application needs it, then full read-write access to the entire database or storage facility will be included. It’s not possible to provide more specific access to just a part of a traditional (monolithic) server application. This makes it much harder to track all access to data because it can come from anywhere in the application. In the event of a breach, it can also be quite difficult to determine where exactly the breach occurred.
With a Serverless approach to PoLP, each microservice has its own set of permissions, unique to its needs and distinct from other microservices. For example, a single microservice can have exclusive access to a sensitive database. All other microservices, applications and even developers would need to go through this microservice to access the sensitive data. This gives you one location in a large application to monitor and validate requests to ensure they are authorised and auditable.
Serverless permissions can be even more fine-grained, limiting access to only specific types of requests or actions, or even limiting a particular user to specific attributes or rows of data. For example, we can have an access role on a microservice that permits a website registration form to add a single new record per request and nothing else. This makes sense because a registration form would only need to create new registration entries; they should not need to edit an entry nor request past entries. Similarly, we can have a rule that an ‘edit profile’ page can only retrieve a single record at a time and can only update the record that it retrieved. An ‘edit profile’ page should not need to retrieve an entire list of user profiles, for example. If the ‘edit profile’ page is compromised, they would not be able to extract all of your personal data records because this page simply does not have that access.

So, you can see how PoLP can give us very powerful capabilities in terms of managing access and a single ‘gateway’ where we can monitor access to sensitive data.
Logging and Monitoring
Next, let’s look at some AWS services that can help store the monitoring logs we might collect in our ‘exclusive access’ microservice.

Amazon CloudTrail is a service of Amazon Web Services (AWS) that enables “governance, compliance, operational auditing, and risk auditing” of an AWS account. CloudTrail is valuable for security since it enables logging, monitoring, and retention of account activity across the AWS infrastructure. To be clear, it logs all requests to AWS APIs, not to your application APIs. This is still important for security as it will tell us if any developer accounts have been compromised, and it includes logs of requests made to fully managed databases such as DynamoDB.

Amazon CloudWatch provides logs and metrics, specifically monitoring and operational data, of resources, applications, and services running on AWS. For example, logs generated within your microservices will be sent to CloudWatch. Logs are always encrypted and have a retention setting to delete them automatically after a configurable amount of time. Alternatively, logs can be exported to S3, where a lifecycle policy can move them to cheaper archive storage.

Amazon Simple Storage Service (S3) can be used to store and retrieve data, including sensitive data. By default, it does not create access logs, but this feature can be enabled. The logs will tell you which service, account or user performed any action on your files, and it is an essential part of the logging toolchain. Even if we have a microservice with exclusive access to a data store, a developer or admin with sufficient access to the AWS account could potentially still circumvent that restriction and gain direct access to the bucket. S3 logs will provide a record of that.
A great security feature of S3 for logging is the ability to lock all objects to prevent deletion. This feature is called S3 Object Lock. For example, this could prevent someone with access to the S3 bucket from deleting specific logs to cover their tracks.

Amazon Macie uses machine learning and pattern matching to identify and track sensitive data in AWS services such as S3. Macie automatically generates an inventory of Amazon S3 buckets, can flag buckets that are publicly accessible and can scan bucket contents for PII or other sensitive data. Macie tracks sensitive data in a dashboard, and it can send notifications when it discovers sensitive data.
For all of the above logging activities, it is a security best practice to store the logs in a separate AWS account with access limited to the Security team. Application teams will need access to CloudWatch logs for debugging purposes, but there are ways to achieve that in this setup that do not compromise security.
One final security tip is that the Serverless database service QLDB could be considered for storing highly sensitive logs. This is a ledger type database where data’s change history is immutable, effectively ensuring that sensitive logs stored in this service cannot be tampered with. As with all storage services on AWS, data is fully encrypted when stored. The encryption keys can be further protected by providing access only to senior security staff.
Proactive Logging
The services mentioned above are all passive; they store logs and do that very well with encryption and access controls to secure and protect them. But simply storing logs is not going to help react to cybersecurity events in a timely manner. At a minimum, alerts should be configured to notify someone of errors and other high-risk events, and ideally, we would have the means to take more aggressive action when needed.
CloudWatch Alarms – This is a managed notification system triggered by CloudWatch logs. Alerts can either be metric or composite. A metric alarm monitors “a single CloudWatch metric or the result of a math expression based on CloudWatch metrics.” The alarm can be configured to send a notification or create an incident in Systems Manager. Meanwhile, a composite alarm takes other alarms into account and only triggers when all alarm conditions are met. CloudWatch Alarms is a relatively easy way to get the bare minimum notifications for resource and application logs.
CloudWatch Subscriptions – Subscriptions offer a more complex, but also a more powerful way to react to logs. In this scenario, you can subscribe a custom microservice to one or more log groups typically generated by the microservices in your application. Each log will be sent to your monitoring microservice, though filters can help to limit that to only relevant logs and save some cost. For example, when your application microservices write logs, they can include keywords such as “ERROR” or “UNAUTHORISED”. A subscription filter could ignore logs without those keywords, such as debugging or general tracking logs. The monitoring microservice gets a full copy of each log which it can parse for more details, and then it can determine an appropriate action to take. As it is a custom microservice, there are far more options than simple email notifications; some of these are:
- SMS or Slack notifications
- Temporary or permanent ban of a user or system account
- IP Range or geographical blocks
- Stop all access to a particular microservice, database or other resource
- Shut down an entire application and put up a temporary maintenance page
- Or anything else that you can develop in a microservice
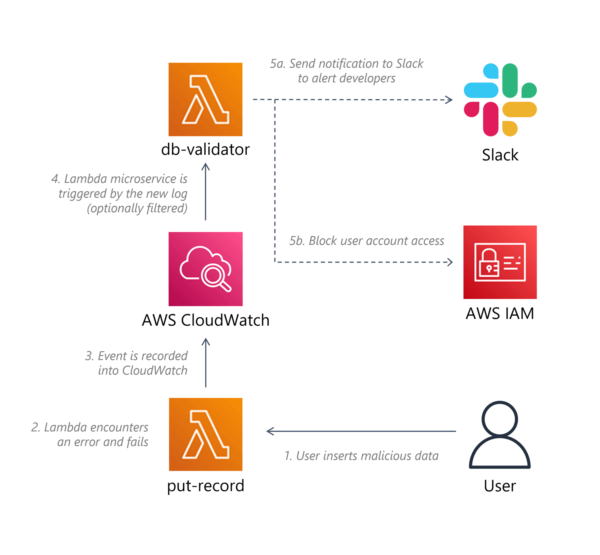
A similar setup can be done for S3 logs as it is possible to trigger a microservice for every file added to an S3 bucket which can then analyse and react to the log in much the same way as a CloudWatch Subscription.
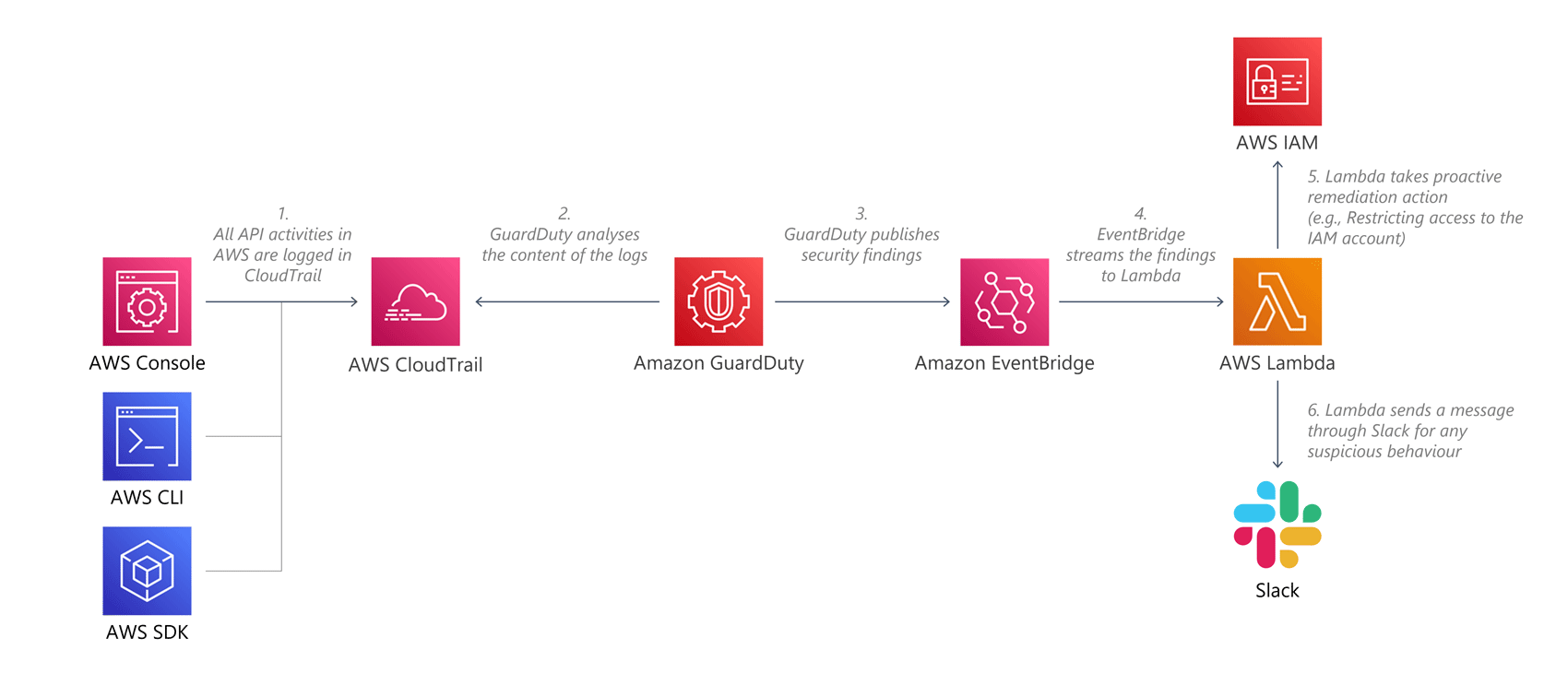
Macie events are logged to EventBridge, which can be similarly automated with microservices responding to events and automatically deleting discovered PII data, tagging it and sending a notification for follow-up, moving it to a more secure S3 bucket, or any other action deemed appropriate by your organisation’s security policies.

GuardDuty can be used to detect malicious access patterns in CloudTrail and S3 logs. CloudTrail can collect thousands of logs a day, and going through them manually, looking for issues is harder than finding a needle in a haystack. GuardDuty uses machine learning, anomaly detection and threat intelligence to analyse your log events, looking for anything suspicious. Automation can be attached to its findings, like CloudWatch subscriptions, sending them to a custom microservice to determine an appropriate course of action to take.
Second Regulatory Requirement: Protecting Data
We should not need to state that everything should be encrypted, which is especially easy for Serverless projects as all Serverless and fully managed services include end-to-end encryption by default in the service. This encryption is provided for free, and without noticeable overheads, so there is really no reason not to use it. Besides the default option that typically uses encryption keys managed by AWS, enterprises can opt to use more advanced options such as custom encryption keys and dedicated encryption hardware devices called CloudHSM, though these are not Serverless.
Some examples include:
- The cloud service Lambda, which hosts microservices, only supports secure connections over HTTPS.
- Lambda environment variables are encrypted at rest. While there are encryption helpers for additional protection, it is better practice to use a dedicated service to store sensitive parameters.
- The storage service S3 and the DynamoDB database service have many options for encrypting data at rest and in transit. This includes encryption with keys owned and managed by the service, keys managed by AWS in the KMS service in your account, and keys that you can create and manage yourself in KMS.
- S3 can additionally be configured to reject any incoming data or requests for data not arriving over an encrypted channel.
Real-Time Controls
Many organisations use manual processes and rules-based automation together in identifying and safeguarding PII. This requires the organisation to know exactly which files contain PII data, but that might not always be the case. With S3 Object Lambda, we can automatically transform S3 data as it is retrieved through a request. S3 Object Lambda is both able to detect and redact PII data.
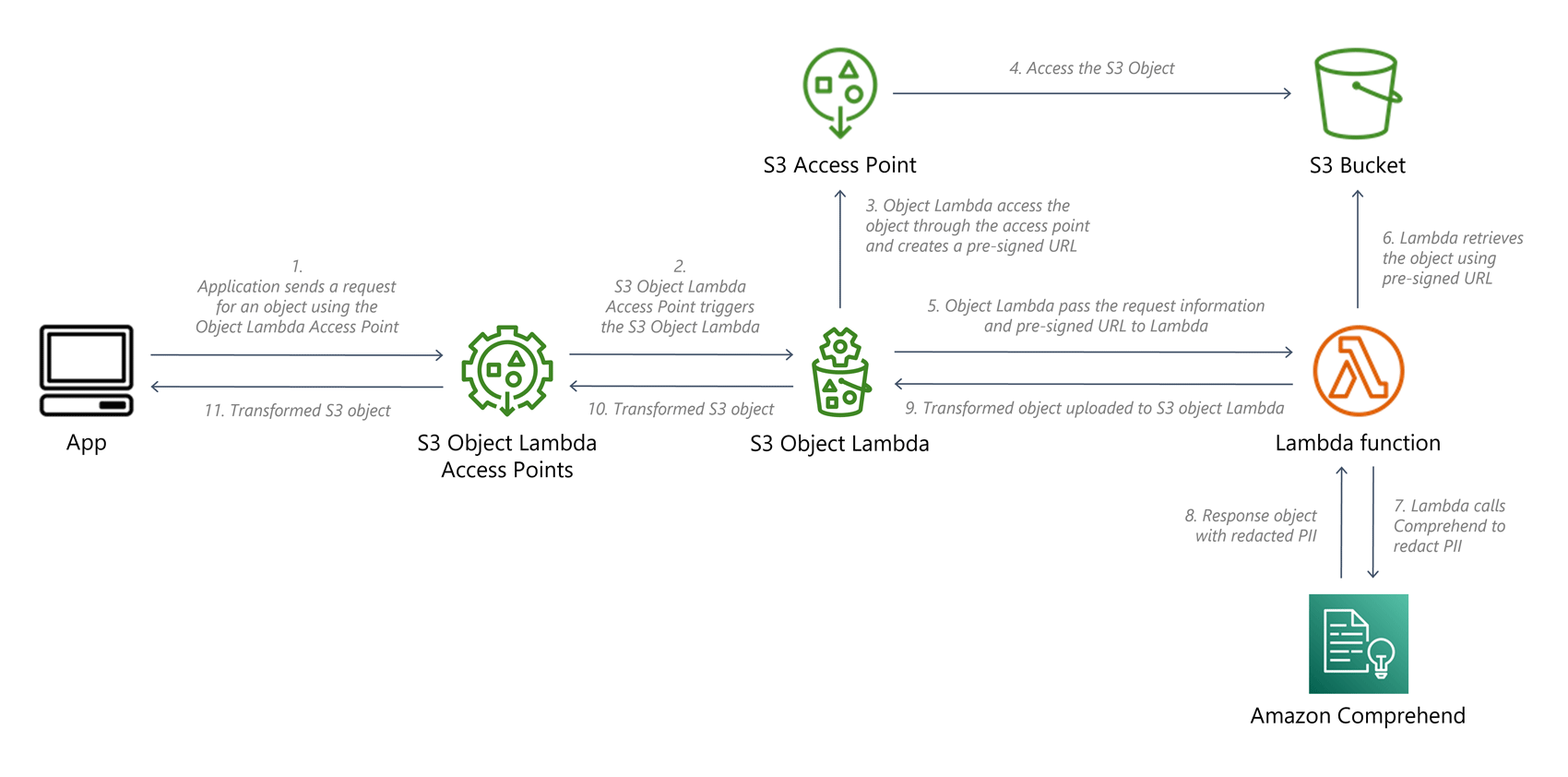
Two common use cases for this feature are:
- Denying access to data if a user or system without PII access authorisation tries to download it. For example, suppose an application has a facility to upload and download project documents, and someone accidentally uploads a file containing PII data. In that case, we can automatically block any external users that might have access to a project from downloading the document containing PII data without having to validate all uploads manually.
- On the fly redacting of PII data from requested documents. For example, PII data could be replaced by tokens to anonymise the data for certain data science activities, or it could delete the PII data from the document entirely as a security measure.
Tokenisation
Tokenisation is a data security strategy whereby we transform a piece of data into a random set of characters. Often, tokens replace valuable data such as credit card information or Social Security numbers. Encryption uses a mathematical process to transform data, so it still contains the original data. Tokenisation replaces the data entirely. This process can be random, making it impossible to revert, or it can use a token vault to remember relationships between tokens and sensitive data. It is an effective strategy to anonymise sensitive data without making it unusable for further processing.
For example:
| PII Data | Tokenised Data |
|---|---|
| Record 1:
Name: Mary Smith | Record 1: Name: tt3034t hg340w3 |
| Record 2:
Name: Jane Smith | Record 2: Name: 34gg9k4r gk030ofs |
This data can no longer be used to identify a particular person while the relationships between the records are maintained. Such relationships are often essential for deriving insights through analytics or other data science activities.
Third Regulatory Requirement: Retaining Data
Storage service S3’s Lifecycle policies enable you to automatically review objects within your S3 buckets and have them moved to Glacier or deleted based on their upload dates and configurable schedules. Implementing good lifecycle policies will help increase data security. Optimal lifecycle policies can ensure that sensitive information is not retained for periods longer than necessary. For example, you can automate the deletion of periodic logs after a week or move last year’s financial records to significantly more cost-effective archive storage.
S3 also has a related feature called Object Lock which can enable the storing of data using a ‘write-once-read-many’ model. This model makes such data very difficult to delete for a fixed amount of time or indefinitely. Even the root user of the AWS account is unable to delete such data, though the bucket itself can still be deleted. This additional protection against data deletion is especially relevant for security and access logs, for example.
The fully managed Database DynamoDB has a feature called Time to Live (TTL). This enables you to define a per-item timestamp that determines when that item is no longer needed. DynamoDB automatically deletes the item from your table shortly after the specified timestamp without consuming any write throughput. This feature is commonly used to remove stale data from a database used for dashboards, but it can also be used to manage the retention of sensitive data.
Conclusion
The cloud, especially Serverless in the cloud, offers many tools to support your organisation’s privacy compliance and data security efforts. We always advocate investing heavily in precautionary measures to ensure that your organisation is protected, whether it be through process, people or technology. Nonetheless, despite having the best possible controls in place, no one is ever 100% protected, especially in today’s fast-moving technology environment. As a result, measures should be implemented to deal with potential future breaches, and plans created, so people and processes are able to address them and remediate their impact with as little damage as possible.

Thomas is a Lead Consultant at Sourced with over 18 years of experience in delivering digital products. He gained a passion for evangelising Serverless architecture through his enthusiasm for cloud and entry into the AWS Ambassador programme.


