
Introduction
On our website you will find a two-part blog published on the protection of sensitive data, such as Personally Identifiable Information (PII), in the cloud. The first, focused on the nature of PII and associated regulatory requirements, and the second looked at how a serverless architecture can aid compliance.
Much of the guidance in the second post centred on activity linked to Amazon Simple Storage Service (S3), and it briefly touched on the use of S3 Object Lambda to automatically transform S3 data as it’s retrieved through a request. Here, we expand on S3 Object Lambda with some practical examples surrounding its use. Before we look at this in detail, it’s important to understand both S3 and Amazon Web Services (AWS) Lambda, and how they power S3 Object Lambda
Amazon Simple Storage Service (S3)
S3 is a popular cloud storage service used by organisations to store a range of data. Organisations use it for its high data availability, performance, durability, and practically unlimited scalability. In S3, we create and store data in a Bucket – a private resource where we can control access. Files stored in an S3 bucket are called objects. We can add, retrieve and delete objects, as well as configure access, tags and other settings.
AWS Lambda
Lambda is a compute service where we run custom code without the need to provision or manage servers. A piece of code deployed to Lambda is called a Lambda Function, also known as microservices or Lambdas.
Both S3 and Lambda are serverless services. This means that the cloud provider fully manages them, and they only bill for actual utilisation, not for idle time or availability. We configure the Bucket or Function, upload our data or deploy our code, pay for the stored amount or per execution, and everything else is taken care of by the cloud provider.
S3 Object Lambda
S3 Object Lambda is a feature that links objects in an S3 Bucket with a Lambda Function. Typically, objects are retrieved or downloaded directly from S3, however this feature acts as a kind of proxy. When an object request arrives, it will pass the request to the Lambda Function instead of returning the response directly. The Function then has the opportunity to process the object before returning a modified version of the object to the requestor.
Next, we look at a few scenarios that this feature can be used to protect sensitive data.
Scenario 1: Each Team Requires a Different View of the Data
Organisations today are undeniably dependent on data in almost every project. It is common for multiple projects to use the same data sets. Different users and applications will have different needs and likely be assigned different data access levels.
Consider Team A, which is storing user data in an S3 bucket, and Team B which requires access to the data. Team B also need an internationally formatted phone number instead of the default local format that Team A uses.
Data in Team A’s S3 bucket:
{
"name":"Mr. John Doe",
"age":"29",
"country":"Singapore",
"address": "9000 Stadium Road",
"department": "Games",
"email": "John.Doe@gmail.com",
"username":"John_Doe_29",
"phone": "91234567"
}Team A could update the data to use the international format or add another attribute containing the international format. This will likely result in code changes to existing applications and might impact applications that expect the current record format. Alternatively, Team A could create a copy of the data which uses an international format. As a result it would mean both teams must maintain two data sets going forward.
Using S3 Object Lambda, we can achieve the desired outcome while avoiding these downsides:
- Team B requests for an object
- S3 Object Lambda passes the requested object to a Lambda Function
- The Function identifies the country and prefixes the phone number with the appropriate country code
- S3 Object Lambda returns the modified object to Team B
Transformed data in response to Team B:
{
"name":"Mr. John Doe",
"age":"29",
"country":"Singapore", //"Singapore" = "+65"
"address": "9000 Stadium Road",
"department": "Games",
"email": "John.Doe@gmail.com",
"username":"John_Doe_29",
"phone": "+6591234567"
}Scenario 2: Redacted Data Required By a Different Team
Organisations looking to manage potential non-compliance need some form of moderation to assess new files that are considered sensitive. Once identified, the file can be deleted, redacted or flagged as containing sensitive data. For redacting, the organisation may want to retain the original data for specific teams or audit purposes. In this case, the redacted version will need to be stored separately, resulting in two copies of the files that need to be maintained.
Controls and permissions need to be in place to ensure only limited authorised users can access the original or flagged files, while the redacted files can be made available more widely within the organisation. This approach often requires considerable manual effort, which can be especially challenging for organisations with limited resources.
In the below example, an organisation’s marketing partner requires the names, email addresses, and departments of the organisation’s users to run a marketing campaign. They also need this data to be in a comma-separated values (CSV) format. The organisation stores the original data as JavaScript Object Notation (JSON) in an S3 Bucket.
If the marketing partner uses the original data, they would need to convert the file to CSV format and this includes sensitive PII data not required to execute their campaign – not ideal for privacy regulation compliance.
Original JSON data:
{
"name":"Mr. John Doe",
"age":"29", //not required for the campaign
"country":"Singapore", //not required for the campaign
"address": "9000 Crona Road", //not required for the campaign
"department": "Games",
"email": "John.Doe@gmail.com",
"username":"John_Doe_29", //not required for the campaign
"phone": "1-234-567-8900" //not required for the campaign
}We could process all the original data, redact it to meet the campaign’s needs, and store the redacted data in a separate bucket to which the marketing partner is given access. The issue with this approach is that each request results in another data sub-set that needs to be managed and maintained. A sub-set that still contains PII data needs appropriate measures to be safeguarded and monitored. This will increase overhead counts and costs to the organisation.
Below is an example where S3 Object Lambda can offer a more cost-effective solution.

In this architecture, the marketing partner requests data from an S3 Object Lambda endpoint instead of directly from an S3 bucket. The remove-pii Lambda function will redact the unnecessary PII data and convert the format to CSV before returning it to the marketing partner.
CSV Data returned to the marketing partner:
"name", "department", "email" "Mr. John Doe", "Games", "John.Doe@gmail.com" ...
Integrating Amazon Comprehend
The above scenarios assume a fixed or at least predictable format and set of attributes are used in the data. This helps us keep the solution simple and use conditional matching to identify the attributes and remove or change the values.
But what if we need to expect any format and files may or may not contain PII data? This is where Lambda’s capability to integrate other AWS services such as Comprehend can provide a solution.
Amazon Comprehend is a fully managed natural language processing service that uses machine learning (ML) to identify meaning and insights in a body of text. More specifically for this use case, we can use Comprehend to detect and redact personally identifiable information (PII) in files. No ML experience is required; a request containing a body of text is sent to the service, which responds with insights that can be acted upon.
Below is a sample request text that was sent to Comprehend and its corresponding response:
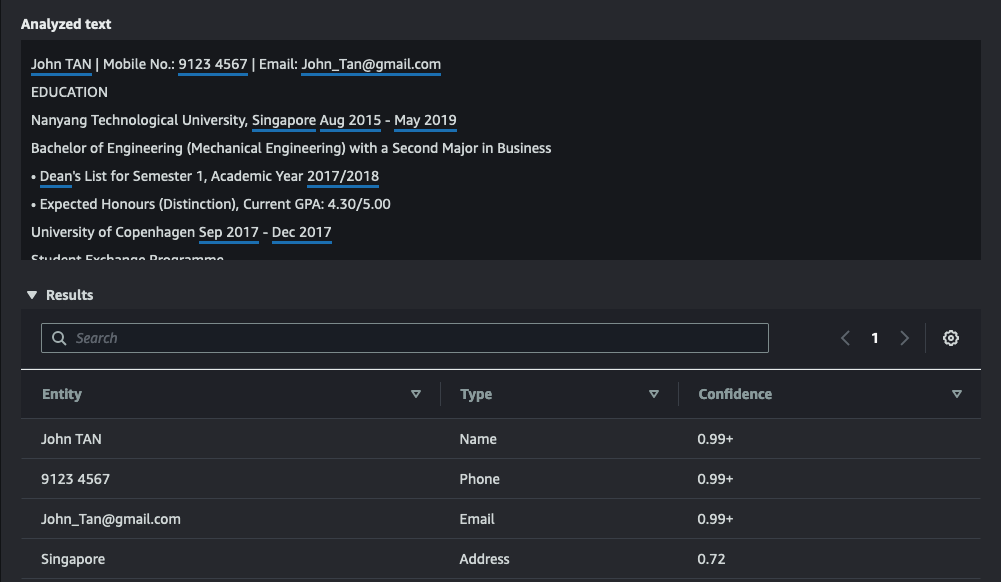
The results are displayed in the AWS Console interface. When a Lambda Function interacts with Comprehend, the response is in JSON, which can be acted upon programmatically. The result is that unpredictable bodies of standard text are automatically converted to a format that can be easily read and interacted with by a Lambda Function.

In this architecture workflow:
- The marketing partner requests data from the S3 Object Lambda endpoint instead of directly from the S3 Bucket, as seen in other examples.
- S3 Object Lambda passes the request to the remove-pii Lambda Function .
- The Function retrieves the original data from the S3 Bucket.
- The integrated Comprehend automatically detects any PII data (DetectPiiEntities) and returns the insights.
- The Function uses the insights to redact the PII data and transform the result into CSV format.
- The redacted CSV data is returned to the marketing partner.
CSV Data returned to the marketing partner:
"name", "department", "email" "Mr. John Doe", "Games", "John.Doe@gmail.com" ...
Challenge: The Latency Benchmark
The challenge of S3 Object Lambda is that it creates additional steps between the request and the response, which inevitably adds latency, slowing down the experience for the requestor.
The table below shows the time taken for directly accessing an S3 object compared to one accessed via S3 Object Lambda. Different Lambda memory configurations were also benchmarked using 128MB, 512MB and 1024MB of memory. The sample JSON file that was requested is 22.2KB and contains 100 JSON objects of randomly generated data. The milliseconds noted in each benchmark are an average taken over 20 distinct requests.
| Type | Time taken in milliseconds | ||
|---|---|---|---|
| 128MB | 512MB | 1024MB | |
Direct S3 GET request (no Lambda Function or processing involved) | 28 | 28 | 28 |
S3 Object Lambda GET request processed in Lambda (removing attributes with key-matching) | 332 | 152 | 117 |
S3 Object Lambda GET request with integrated Comprehend (removing attributes with ML) | 1350 | 423 | 329 |
From the table, we can see that S3 Object Lambda adds considerable latency to the request, especially when integrated with Comprehend. Increasing the memory allocated to Lambda does seem to reduce the latency. Developers are recommended to benchmark scenarios to find the optimal memory allocation for their Function and use case.
Conclusion
There are several ways to address sensitive data protection, but most come at a cost – such as creating and maintaining multiple data sets for different groups. S3 Object Lambda offers a new, serverless approach to this problem that can provide benefits for specific use cases. It avoids having duplicate data sets and enables a far higher degree of automation through custom code and integrated ML services. However, it comes at the cost of latency, which needs to be considered with respect to user experience.

Okkar is an Associate Consultant at Sourced with 2 years of professional experience in architecting and implementing cloud solutions. He enjoys researching the latest technology trends and applying them to client projects.

Thomas is a Lead Consultant at Sourced with over 18 years of experience in delivering digital products. He gained a passion for evangelising Serverless architecture through his enthusiasm for cloud and entry into the AWS Ambassador programme.


