
Introduction
Earlier in the year we worked with one of our Australian media clients to provide a streaming platform capability to service a subset of their online listeners during their national music poll event. Although an Australian event, listeners tune in from all over the world on a wide range of devices, operating systems and applications.
In this post, we will walk through how a scalable solution was designed and implemented on Amazon Web Services (AWS) to support up to 100,000 concurrent listeners across both Advanced Audio Coding (AAC) and MPEG-1 Audio Layer III (MP3) formats.
Understanding Common Audio Streaming Technologies
Prior to diving into the internals of the solution, it is important to understand some of the common audio streaming technologies in use today. Generally speaking, you are likely to encounter one of these three core technology stacks;
HTTP Live Streaming
HTTP Live Streaming (HLS) is an HTTP-based media streaming communications protocol designed and developed by Apple. Support is widespread in many streaming media servers with client implementations available in a wide variety of browser and client implementations, including Firefox and Google Chrome.
At a high level, HLS functions by splitting up the origin stream into a sequence of small HTTP-based file downloads with each download loading one chunk of an overall potentially unbounded transport stream.
Because it is based on the standard HTTP protocol, HLS can function through any network or proxy layer that permits standard HTTP traffic as well as allowing content to be served from conventional HTTP servers. Furthermore, it also benefits from wide support by many popular HTTP-based content delivery network providers.
HLS provides several additional features such as providing mechanisms for audio players to adapt to unreliable network conditions without causing user-visible playback stalling, a simple Digital Rights Management (DRM) implementation and fast-forward and rewind capabilities.
Traditional / Legacy Audio Encoded Streams Delivered Over HTTP
Prior to the development and availability of HLS, audio streams were primarily delivered over HTTP using popular streaming tools such as Shoutcast and Icecast. These services function by advertising an HTTP endpoint and URL that is retrieved using an HTTP GET request by the listening client.
Upon a successful GET request, the browser or device checks the Content-Type header to understand the encoding of the stream, which it will be able to decode directly or pass onto another application to allow listening.
The below curl output to a popular SHOUTcast-delivered stream shows the HTTP request and associated headers for an AAC Plus stream.
$ curl -o /dev/null -v http://live-radio02.mediaexample.com/2TJW/aac/ Trying 102.52.193.68... * TCP_NODELAY set * Connected to live-radio02.mediaexample.com (102.52,.193.68) port 80 (#0) > GET /2TJW/aac/ HTTP/1.1 > Host: live-radio02.mediaexample.com > User-Agent: curl/7.54.0 > Accept: */* > < HTTP/1.1 200 OK < Server: nginx/1.14.0 < Date: Thu, 07 Feb 2019 05:54:48 GMT < Content-Type: audio/aacp < Connection: close < icy-notice1: <BR>This stream requires <a href="http://www.winamp.com">Winamp</a><BR> < icy-notice2: SHOUTcast DNAS/posix(linux x64) v2.4.7.256<BR> < icy-name: Triple J NSW < icy-genre: Misc < icy-br: 64 < icy-url: http://www.abc.net.au/radio < icy-pub: 0 < X-Clacks-Overhead: GNU Terry Pratchett
Given the nature of this technology, where the stream is effectively a never-ending file download, it presents a number of limitations. These include a lack of support by common CDN providers as well as a lack of more advanced features provided by HLS, such as rewinding and dynamic stream quality adjustment.
Although it has a number of limitations in its capabilities, one of its core strengths lies in its simplicity, specifically in that any device that can issue an HTTP GET request and decode a set of common audio formats such as MP3, AAC or OGG, can use the published stream.
As such, solutions built on this technology will benefit from extensive support across a wide range of devices dating back many years and continued support for many years to come.
RTP and Adobe Flash Related Services
The final technology stack you may encounter are those based on end-of-life technologies such as those delivered and decoded using the Adobe Flash software suite or those leveraging non web protocols such as Real-time Transport Protocol (RTP), which uses UDP to transfer the audio stream data to network clients.
Given that these solutions are rapidly being phased out of use, or are not suited for web audio streaming, we won’t delve any further into their internal functionality.
Solution Requirements
Now that we have a solid understanding of the common streaming technologies available today, we can look to the challenge we had to solve.
In this particular case, our client was concerned that the upcoming event would be extremely popular and the current solution for providing quality audio streams to legacy streaming devices through a third party, hosted in a traditional data center with limited network capacity, would not provide the level of audio quality users had come to expect. They were also concerned that the current solution would not provide the level of platform scalability required for the expected load.
Before moving on, it’s worth noting that in this context legacy is defined as any device that is unable to use the existing HLS audio streams delivered via their existing CDN partner, or devices that lack the ability to decode certain audio formats.
In this particular environment, the clients using the platform included;
- Traditional MP3/AAC compatible Internet radio devices and applications;
- Older style web applications that hand off M3U and similar playlist files for external applications; and
- Some smart speakers such as Google Home (that for technical and licensing reasons were using the MP3 stream on this platform).
As such, the client engaged us to assist in the building and deployment of an AWS-based solution to serve the audio streams on the day of the event.
Solution Technology Stack
In this section, we’ll walk through the delivered technology stack that provided this service.
Content Origin – On-Premise Audio Encoders
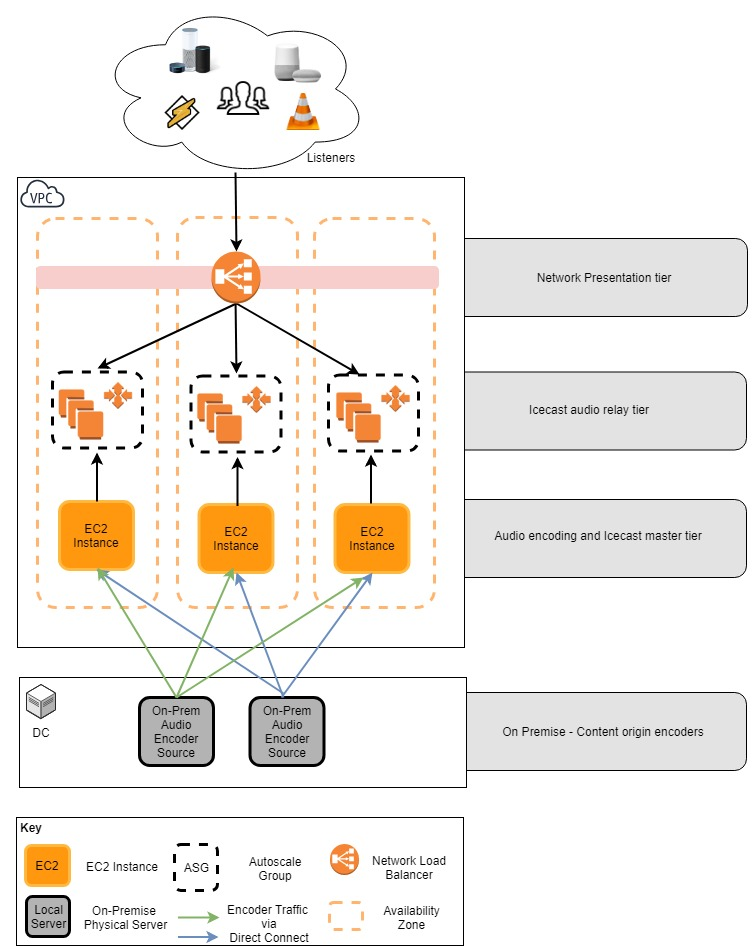
The origin audio stream was delivered by the clients on-premise audio encoders. These physical devices were able to reach AWS over their existing Direct Connect link to their AWS VPCs.
Although a black box device to the cloud team, these devices were configured to produce a set of UDP audio streams to each of the AWS Encoder master instances. These were running on EC2 instances in each of ap-southeast-2 region’s three availability zones.
These UDP streams were encoded at origin as “MPEG 1 – Layer II – 384 Kbs @ 44 kHz”.
Encoder and Streaming Master Tier
The next part of the solution was the encoding and streaming master tiers.
Comprising 3 x EC2 Instances running Ubuntu Linux, one in each of the ap-southeast-2 region’s Availability Zones (AZs). This layer has two core responsibilities;
- Encoding the source audio stream produced by the origin on-premise encoders to a number of different formats; and
- Submitting the audio streams to the locally hosted shoutcast master servers for later distribution to the shoutcast relays.
These were configured as follows;
Encoder Configuration
Initially leveraging a commercial encoding product that was proving to be problematic on the group’s Standard Operating Environment (SOE), we decided to use the ever-versatile ffmepg media encoding tool to handle all transcoding operations.
This was implemented by having each EC2 instance run a set of ffmpeg processes listening on a set of UDP ports that were being targeted by the on-premise encoder streams. Once the streams connected to the ffmpeg processes, they would then convert the source MPEG 1 – Layer II – 384 Kbs @ 44 kHz streams into the following output streams;
- 96k MP3 Audio @ 44 kHz; and
- 128k AAC Audio @ 44 kHz.
Once the origin stream had been encoded, we leveraged ffmpeg’s Icecast output support to send the output to an instance of the Icecast master server running locally on each EC2 instance.
In the below code snippet, we show the ffmpeg command used to listen on port 5001 for an inbound audio stream, converting it to AAC and then publishing it to the local Icecast master.
ffmpeg -stats -i udp://127.0.0.1:5001 -acodec libfdk_aac -b:a 128k -ac 2 -ar 44100 \ -content_type audio/aac -legacy_icecast 1 -strict -2 -f adts \ icecast://username:password@localhost:8085/event_a_aac
To ensure that each of these processes were resilient against failure on the Linux side, we used systemd’s monitoring and restart functionality to ensure that if the process went offline it was restarted in less than a second.
Icecast master configuration
As mentioned in the previous section, once the audio streams had been encoded to the required formats, they were passed onto local instances of the Icecast masters.
For those unfamiliar with Icecast, it is described by the authors as;
Icecast is a streaming media server which currently supports Ogg Vorbis and MP3 audio streams. It can be used to create an Internet radio station or a privately running jukebox and many things in between. It is very versatile in that new formats can be added relatively easily and supports open standards for communication and interaction.
Icecast.org FAQ
Leveraging the Icecast software, we were able to distribute the encoded audio streams upstream to a set of Icecast relay servers that would be responsible for servicing listeners requests in a scale-out pattern to provide capacity and fault tolerance.
Audio Relay and Network Presentation Tier
The final part of the solution was the relay and network presentation tier, comprised of two main components:
- A set of AZ specific Auto Scaling Groups that would launch EC2 instances configured as Icecast relay servers. These would relay the audio streams produced from their AZ specific Icecast master server. To provide additional logging data and to implement connect limits to individual servers, we fronted these Icecast streams with nginx prior to exposing them as web resources over HTTP; and
- An AWS Network Load Balancer (NLB) that served as the solutions entry point by fronting all Icecast relay servers as they scaled out and distributed connections to them efficiently. Prior to the event, the client updated their M3U playlist files and other references to point to the NLB to direct traffic to the platform in the week leading up to the event.
By selecting this topology, we were able to ensure that the streams were fault tolerant both at a Linux OS level and against an AZ failure. In addition, we were able scale out when required by increasing the relay tiers Auto Scale Group instance count in response to increased listener demand.
The diagram below shows the AWS topology for the solution.
Preparing For The Main Event
Given the high visibility of the event, it was critical to ensure that the platform was well monitored to understand how the solution was performing.
As such we introduced two technologies.
Centralised Logging with Splunk
We installed the Splunk Universal Forwarder on all the Linux instances that were launched in the environment to provide a centralised logging capability. In addition, we leveraged the Splunk UNIX Add-On and a set of application specific input configurations to ingest the Icecast and Nginx log files. This provided us with not only application health metrics, but also a rich amount of listener metadata such as device type and location that could be used for design decisions in subsequent years.
Datadog Monitoring
In addition to the centralised logging capability, Datadog was leveraged to provide performance and availability metrics for both the AWS and Linux resources, the latter being provided via the Datadog agent installed on all Linux hosts at launch time. Using Datadog we were able to build a number of high quality operational dashboards that provided deep levels of visibility into the number of listeners on the platform as well as how each component in the solution was performing.
Event Day Observations and Outcomes
In the weeks prior to the event, with the assistance of the client, we cut over the existing audio playlists for the wider radio network to the new solution so that we were serving live traffic early, giving us time to fine-tune some of the dashboards. Two days prior to the event we increased the relay Auto Scale Groups to 18 EC2 instances in total. We identified this configuration as being ideal for the event through prior load testing using a number of different instance type configurations.
The event itself was a great success and being able to spend some time in the studio as well as with the technology teams themselves was lots of fun. Unfortunately we didn’t reach the 100,000 listeners expected on this particular platform as more listeners tuned in to the event via the clients primary HLS stream. However, we were able to prove out the solution as a reusable pattern suitable for future events.
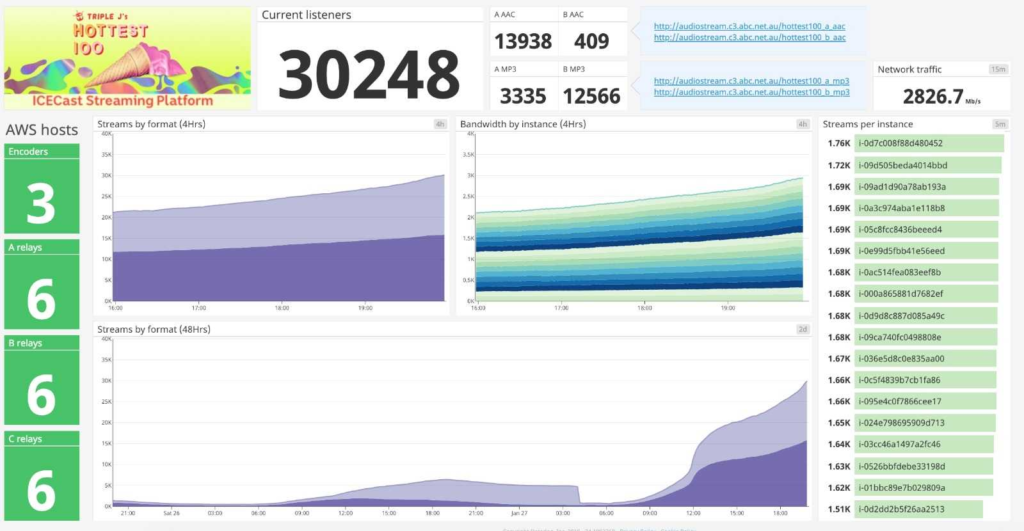
I’ve included a screenshot of the operational Datadog dashboard showing the peak listener load for the day at 30,248 listeners. This shows Datadog’s flexibility in aggregating metrics from all the solution’s components to help build rich real-time dashboards.
Future Enhancements
Although happy with how the solution was delivered and performed on the day, we are always looking for ways to enhance and optimise the solutions we deliver for our clients. For the next event, we feel that we would look to make the following architectural changes;
Leverage Containers for the Encoding Tier
Although the encoding tier is relatively static with very few changes needing to be made outside of encoding configuration changes, we feel that migrating it from a set of single EC2 instances to containers running on the Elastic Container Service (ECS) or a similar orchestration platform would provide us with more effective use of the underlying EC2 instance resources as well as enabling us to release configuration changes faster than the current solution allows.
Use Nitro Based Instances for Icecast Relays
The Icecast relay servers used for serving the clients on the day were of the C4 family and provided suitable network throughput for our needs after some extensive performance tests. However looking through some of the network benchmark metrics provided by a number of third parties, it was obvious that the newer Nitro based instances (ie C5/M5/T3) provided significant network performance increases and would provide more network capability with fewer instances. Unfortunately for this particular solution, the client’s Linux SOE was not certified with the Nitro platform and it ruled them out for the event. However, we would look to leverage them for future projects alongside an Auto Scaling Group policy for the relay tier that would move the platform away from scheduled scaling prior to the event.
Evaluate Route53 Load Distribution as an Alternative to the NLB
The current solution leverages an NLB for load distribution from the end user to the Icecast relays. As an alternative to the NLB, we’d consider evaluating the load distribution performance and capability of just Route53 itself to a set of internet facing relay instances. This could offer some additional flexibility when managing inbound connections and possibly reduce some costs in the absence of a busy NLB.
Acknowledgements
This particular solution and event were possible due to the hard work of a number of individuals both on the client side and the Sourced side. I’d like to acknowledge the hard work of former Sourced team member Ben Brazier, who has moved on to new pastures. The amount of work he put into this solution cannot be understated and is greatly appreciated.
References
The following documents were used when building this solution and writing this blog post.
- HTTP_Live_Streaming
- SHOUTcast
- Akamai – HLS
- Real-time Transport Protocol
- Icecast – Basic setup
- AAC – Advanced Audio Coding
- Gary Mcgath – Streaming protocols
- Google home – Audio features
- Singlebrook.com – Auto restart crashed service with systemd
- MPEG 1 Audio Layer II
- EC2 Network performance cheat sheet
- Splunk UNIX TA
- Datadog AWS integration
- Amazon EC2 Update – Additional Instance Types, Nitro System, and CPU Options
- James Hamilton – AWS Nitro system
- NGINX

Keiran Sweet is a Principal Consultant with Sourced Group and is currently based in Sydney, Australia. He works with customers to automate more and integrate with next-generation technologies.


