
Cloud consultant Asanka Nissanka looks at how to use AWS Fault Injection Simulator (FIS) for chaos testing.
One of the most common misconceptions about cloud-based systems is that they are inherently reliable and don’t require failure testing. Yet under the shared responsibility model, cloud vendors are only responsible for reliability of the cloud, not workloads in the cloud. This blogpost looks at how to enhance the reliability of workloads in Amazon Web Services (AWS) with failure in mind.
Firstly, all workloads should be designed to withstand failures. Ten years after the launch of Amazon, CTO Werner Vogels said a key lesson he’d learnt was that:
Failures are a given and everything will eventually fail over time: from routers to hard disks, from operating systems to memory units corrupting TCP packets, from transient errors to permanent failures. This is a given, whether you are using the highest-quality hardware or lowest cost components.
If you’re looking for an overview of design principles to manage the risk of failure, the reliability pillar of the Well-Architected Framework is a good place to start. Here, we drill down into failure simulation using AWS Fault Injection Simulator (FIS).
What is failure simulation?
The chaos engineering discipline advocates experimenting on distributed systems to build confidence in their ability to withstand turbulent conditions. Failure simulation falls within this scope. It’s a testing technique which can be used to validate a system’s resiliency.
Failures are unpredictable and it’s hard to manually induce them. Afterall, we cannot physically start a fire in a data centre to test for an outage. However, we can simulate changes or failures that resemble what might occur in this scenario. For instance, to simulate Availability Zone failure we might cut off the networking in each of the subnets.
While failure simulation is a useful technique, it must be handled carefully in production environments or when used at scale. The execution needs to be closely managed, and important factors to account for include:
- Blast radius definition – Filter and select a subset of resources to be targeted during the experiment.
- Stop experiment – Ensure there is a way to terminate the experiment manually or automatically if something goes wrong.
- Monitoring – Observe each step of the experiment’s progress and set parameters (e.g., start time, end time, duration).
- Security – Safeguard resources and configurations with controlled access.
AWS FIS is a fully managed service with features that address these concerns. It provides a real-world fault injection experience from a centralised console. Reusable experiment templates can be created, incorporating various fault types to simulate outage scenarios with different levels of complexity. Furthermore, FIS provides inbuilt mechanisms to terminate the execution of an experiment before it runs out of control.
Fault injections supported by AWS FIS
AWS FIS currently enables the following fault injections for AWS services:
- Amazon Elastic Compute Cloud (EC2)
- Stop instance
- Reboot instance
- Terminate instance
- Spot instance interruption
- Amazon Elastic Kubernetes Service (EKS)
- Terminate node group instance
- Inject Kubernetes custom resource
- Amazon Relational Database Service (RDS)
- Failover DB cluster
- Reboot DB instance
- AWS Application Programming Interface (API) Errors (Supported only for EC2 API endpoints)
- Internal error
- Throttle error
- Unavailable error
- Custom fault types via Systems Manager (AWS provided public Systems Manager documents (SSM) available)
- Send command
- Start automation execution
- Network
- Disrupt Connectivity
It also provides Pre-configured Simple Systems Manager (SSM) Documents which can be used with the send-command action. Running commands and executing automation via Systems Manager allows multiple failure simulation scenarios of varied complexity to be implemented. However, the FIS console only shows the status of SSM document it invokes. To access full details of the SSM command or automation, we would have to check the Systems Manager.
Three ways to inject faults using Systems Manager
Injecting AWS services with faults is relatively straightforward, as the following examples of SSM documents/automation demonstrate:
- Managed streaming for Apache Kafka (MSK) broker reboot
Use an SSM document of type automation with an execute script step that uses AWS SDK python library (boto3) to call the reboot broker action on an MSK broker instance. - EKS pod delete
Use an SSM document of type automation with an execute script step that uses Kubernetes API server endpoints to get a list of pods in a namespace with certain labels, and randomly delete one.
(Note – AWS FIS recently announced support for the third-party tool – Chaos Mesh, a chaos engineering platform for Kubernetes. This can be used instead of the SSM document-based approach for pod deletion. However, the SSM approach is a useful, simple alternative). - Autoscaling Group Availability Zone failure
Use an SSM document of type automation with multiple steps to get a list of subnets, remove all subnets that belong to a certain Availability Zone (AZ), and roll back to the original state.
(When using SSM documents it’s important to add rollback steps to the actions so the environment can be reset to its original state if AWS self-recovery is not available).
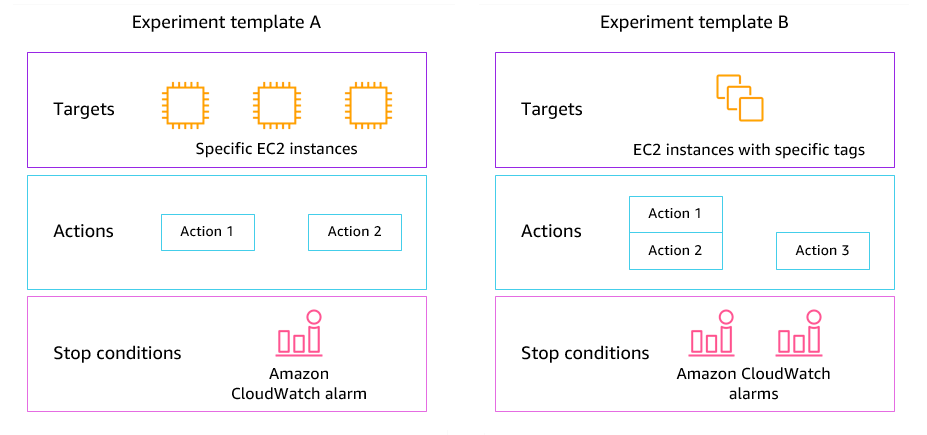
FIS Concepts
FIS terminology is largely self-explanatory, but it’s important to fully understand key concepts before designing and executing failure injections:
- Action – This refers to FIS’ performance of fault injections like those mentioned above. Additional actions include Wait and use of CloudWatch alarms to support the definition of multi-action failure scenarios.
- Target – The AWS resource on which the action is performed is referred to as the target. Specific resources or groups of resources can be selected using filter criteria or tags. In the below example, a filter is used to select resources in an Availability Zone.
{
"path": "Placement.AvailabilityZone",
"values": [
"ap-southeast-1a"
]
}
- Stop condition – This is the kill switch to stop an execution. Currently, we can configure one or many CloudWatch alarms that instruct FIS to stop the execution if triggered.
- Experiment template – A reusable template that defines the failure scenario using actions, targets, and stop conditions.
- Experiment – An execution of the experiment template.
The below diagram from AWS illustrates the anatomy of a FIS experiment template.
Experiment monitoring and security
An experiment’s progress can be monitored via the FIS console or the AWS Command Line Interface (CLI). The start and end times of each action are observed via a timeline, but other tools are needed to monitor the impact of the experiment on the target. Tools like CloudWatch, Grafana, Prometheus, Datadog, and New Relic enable system responses to the failures to be tracked. It’s important to have adequate observability controls in place to monitor the system response and the impact on the user experience. After all, one of the expected outputs of a failure simulation is validating whether enough observability controls are in place.
FIS experiment templates use Identity and Access Management (IAM) roles to perform actions on AWS resources. As with other AWS services, it’s important to follow the least privilege principle here, ensuring the experiment roles are not over-permissive. Different IAM roles can be used for individual templates, with only the required permissions granted. In some instances, it is convenient to establish one shared IAM role across experiments to keep things simple.
Failure Injection with AWS FIS
The following diagram (extracted from AWS documentation) shows a high-level overview of the FIS solution. It outlines the two-step failure simulation process:
- Create experiment templates.
- Execute experiments using experiment templates.
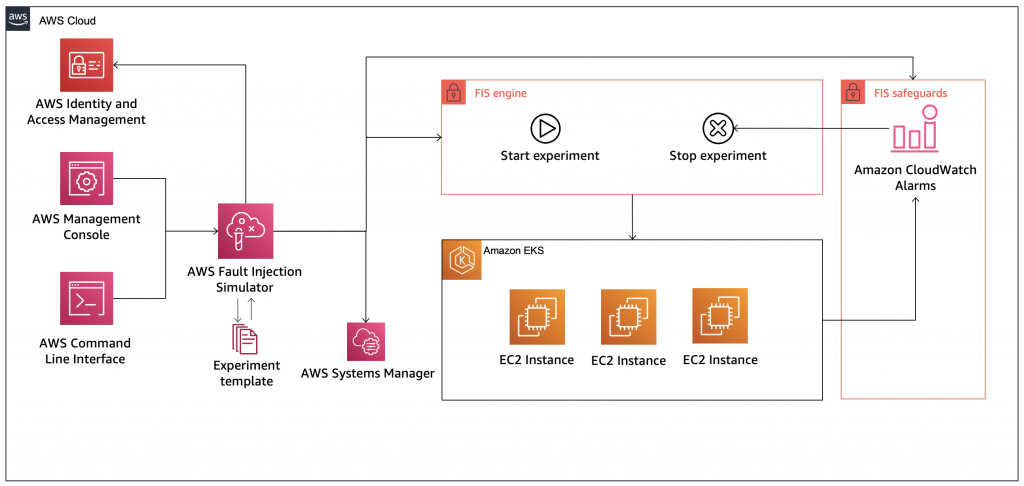
Since fault injection experiments are not a one-time exercise, a documented process should be established. When there are multiple AWS accounts for different workloads and environments (like staging and production) this makes the provisioning of FIS experiment templates easier. Observations need to be recorded during experiments, with project/system backlogs updated with required improvements or changes.
Provisioning FIS Experiment Templates
Infrastructure as Code (IaC) tools like CloudFormation can be used to define FIS experiment templates with parameters based on infrastructure resources. When using multiple AWS accounts, templates can be provisioned via the automation account (if there is one) using CloudFormation StackSets. Alternatively, they can be provisioned directly on the target account. There is no set recommendation for this, so the approach should be based on the organisation’s requirements.
In the example outlined in Figure 3 (below), FIS experiment templates are defined as CloudFormation templates. A continuous integration and delivery (CI/CD) pipeline is used to provision them to target AWS accounts via a management/automation account. It’s also possible to use Customizations for AWS Control Tower (CfCT) to provision FIS templates centrally to multiple AWS accounts within the AWS Organization (Landing Zone).
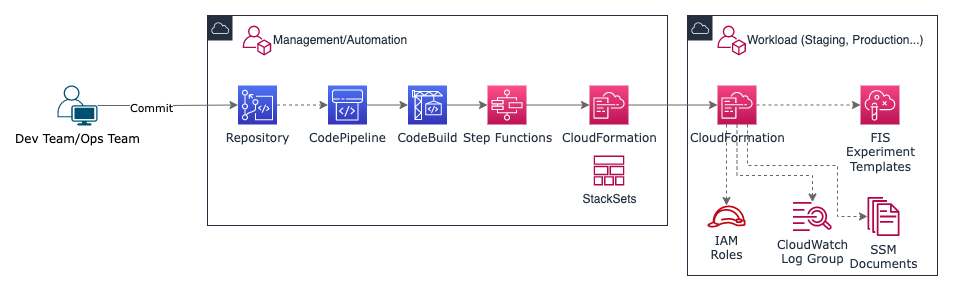
Executing Experiments
When conducting failure simulations, it’s best to define a workflow for repeated execution then record observations for each iteration. Figure 4 outlines an execution workflow we used for an organisation with different workloads/applications across multiple AWS accounts. We defined this process after reviewing several models used by different organisations. There is no hard and fast rule, the approach can be modified according to your needs. In this case, we used a standard worksheet across the different workloads to record observations from each iteration. The FIS experiment template ID is recorded within the worksheet for each failure scenario, enabling easy reference during the process.

Most of the time, these experiments involve joint effort between multiple people on application and infrastructure teams. So, they can form the basis of Chaos Days, an interesting and useful alternative to Game Days.
Secure and effective failure simulation for regulated industries
Failure simulation is a practical way to validate reliability controls, ensuring they respond as expected and satisfy compliance requirements. It can also identify blind spots that may have been missed.
AWS FIS provides a convenient test environment to execute fault injection in a controlled manner. What’s more, the trust boundary can be limited to AWS’ private environment as per the security requirements of regulated industries. AWS is updating FIS at a rapid pace adding support for more native services as well as open-source chaos engineering tools like Chaos Mesh and Litmus Chaos.

Asanka is an experience senior application engineer with 10+ years of industry experience in architecting and implementing cloud-based applications for heterogeneous enterprise environments. With his constant passion for emerging technologies, he was also groomed as a consultant supporting US based customers to design and migrate workloads to cloud. In 2021, AWS (Amazon Web Services) invited him to participate the AWS Community Builder program under the Serverless category for his contributions to the developer community.


