
Introduction
Sourced was recently engaged by a global Financial Services Industry (“FSI”) client to perform a migration of their Pega Platform installations to Microsoft Azure. This initiative was in response to their existing on-premises environment experiencing severe capacity constraints, preventing customer-facing business units from bringing new products to market.
Given the prevalence of Pega within their environment, this resulted in a business case to invest in a reusable pattern which would enable the organisation to eventually migrate the 50+ Pega installations they currently support in a consistent manner. This post illustrates how Sourced was able to leverage reusable patterns on-top of Microsoft’s Azure cloud computing platform to improve performance, reduce cost, and dramatically simplify running the Pega Platform at scale.
Pega Platform Overview
Before we dive too deep into the technical topology of the solution, it’s important to first understand the Pega Platform and the capability it provides to the businesses that use it.
In Pegasystems’ own words:
Pegasystems offers strategic applications for sales, marketing, services and management. Pega applications makes work logical. It seamlessly connects management channels and clients in real time, making it easy to react to any sudden changes.
Financial institutions use Pega for many of their business processes, from marketing to sales automation and customer service.
Pegasystems’ expertise in providing digital process automation makes them a significant player within the financial services industry as their platform has a proven track record of delivering seamless customer experiences across a range of interactions.
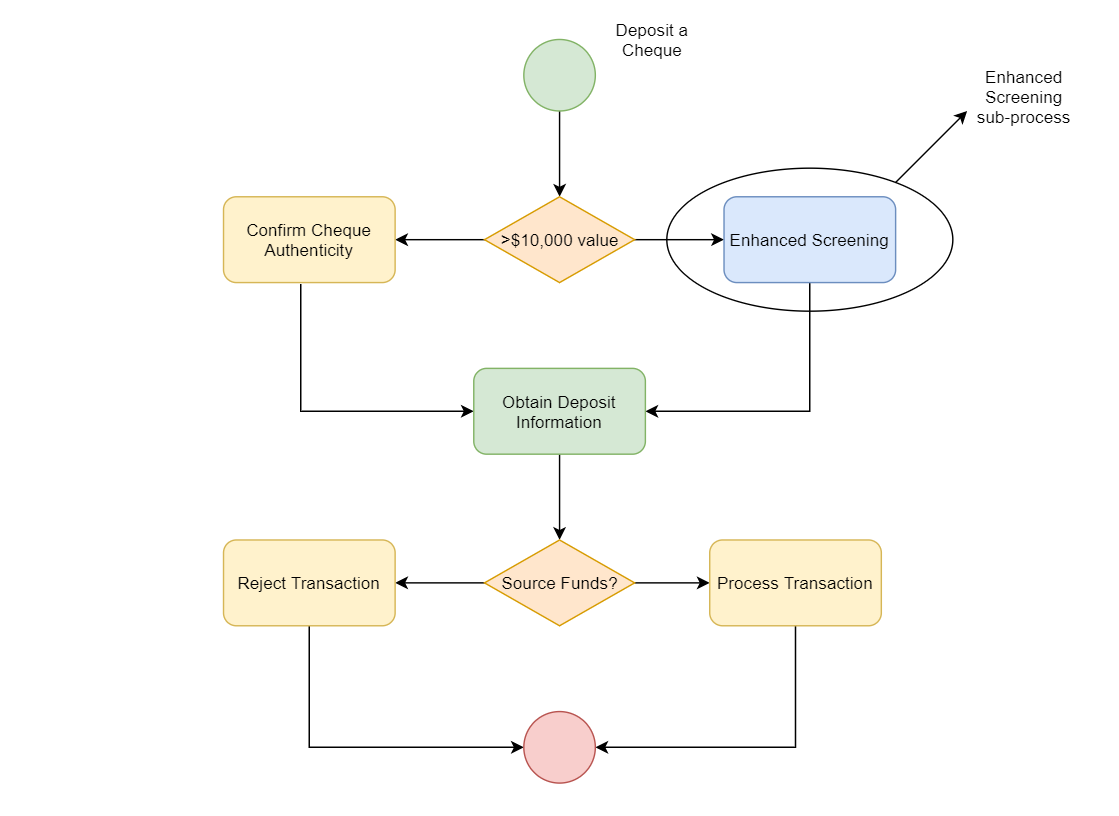
For example, when customers interact with their local bank branches, terminals utilised by front-line bank staff could be driven by Pega-backed workflows. Focusing on a common customer service workflow, the diagram below demonstrates a sample view on how a Pega application may enforce business rules and logic for depositing a cheque:
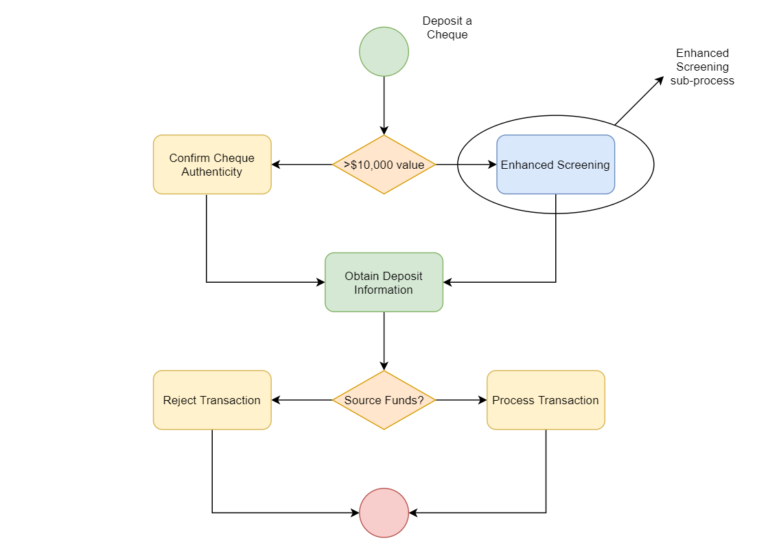
The sample screen flow above demonstrates a process when a customer deposits a cheque at a branch, and follows the life-cycle of the action from beginning to end. The process steps through:
- Initiating the process
- Applying business logic for the verification methodology for the cheque
- For enhanced verification, initiating a sub-process contained within a different flow
- Validating whether the source account has the appropriate funds to accommodate processing the cheque
- Processing or rejecting the transaction
The above represents a simplified use case of a business workflow that could be accommodated by Pega. In reality, these workflows are dramatically more complex, and an organisation providing financial services is likely to have many hundreds of these workflows across a myriad of different business products.
Whilst this example shows a process initiated by a physical customer interaction at a branch, there is a number of other ways processes within Pega can be initiated. These include, but are not limited to:
- Clicking a recommendation in a mobile application
- A back-end workflow for a form submitted through an alternate system
- In batch in response to a time-based event
The development on top of the Pega Platform is not the focus of this post, but it is important to understand that these are involved tasks and there exists a strong community of Pega developers which rely on the availability of Pega environments to develop against business objectives such as the one demonstrated above. This is an important consideration when thinking about how to architect your deployment of Pega Platform for scale.
Understanding the Pega Technology Stack
Pega, at its core, is a Java application that can be run on either Windows or Linux operating systems with application and state data stored in a variety of supported database engines such as Microsoft SQL Server, PostgreSQL, IBM DB2, and Oracle.
Pega’s long standing tradition of flexibility in accommodating deployment patterns has meant a proliferation of different approaches to running Pega within the enterprise. Ultimately, many of these approaches included design decisions which were well intentioned at the time but have failed to meet the scale requirements of an increasingly digitised landscape.
In this particular client’s case, they had chosen to deploy Pega on the following technology stack:
- VMware Virtual Machines on Nutanix hyper-converged infrastructure running Red Hat Enterprise Linux
- Java and JBoss EAP to run the Pega 7 application
- IBM DB2 on IBM Power Series-based hardware for the database tier
This hardware, whilst more than capable of running the software in question, was beginning to fail to meet business needs for the following reasons:
- Capability planning of the underlying infrastructure for the application tier was not a perfect science leading to “VM droughts” where access to new VMs was not possible
- Extreme cost of the database hardware forced co-tenanting which made infrastructure sharing a necessity
- Layers of licensing across the solution was complex and involved multiple vendors
- Consistent approach to automation was not possible as the technology choices were disparate
- Pets approach to managing Pega itself which resulted in a slow cadence for infrastructure and application upgrades
The net result of the above was our client’s technology teams failing to meet the expectations of their business. In a real sense, the business was unable to bring new products and offerings to market as the cost of the underlying technology had the potential to erode forecasted returns on those very products and offers.
Deploying Pega on Azure
The client, who already had an extensive cloud strategy in place around Microsoft Azure, made the decision to re-architect their approach to Pega in alignment with this broader enterprise strategy for cloud. Fortunately, the client’s availability of services in their Azure ecosystem aligned well with the requirements to run Pega. Specifically:
- Azure VM Scale Sets running Red Hat Linux and hardened to their standards were available for deployment
- Java and JBoss EAP could be installed easily on the VM instances from centralised software repositories
- Managed Microsoft SQL Server services were available as Azure SQL Managed Instance
As such, combined with a configuration management strategy utilising Puppet Enterprise, we had the foundations of what we would need to re-architect the client’s approach to Pega in a scaled and resilient manner.
Azure Resource Provisioning
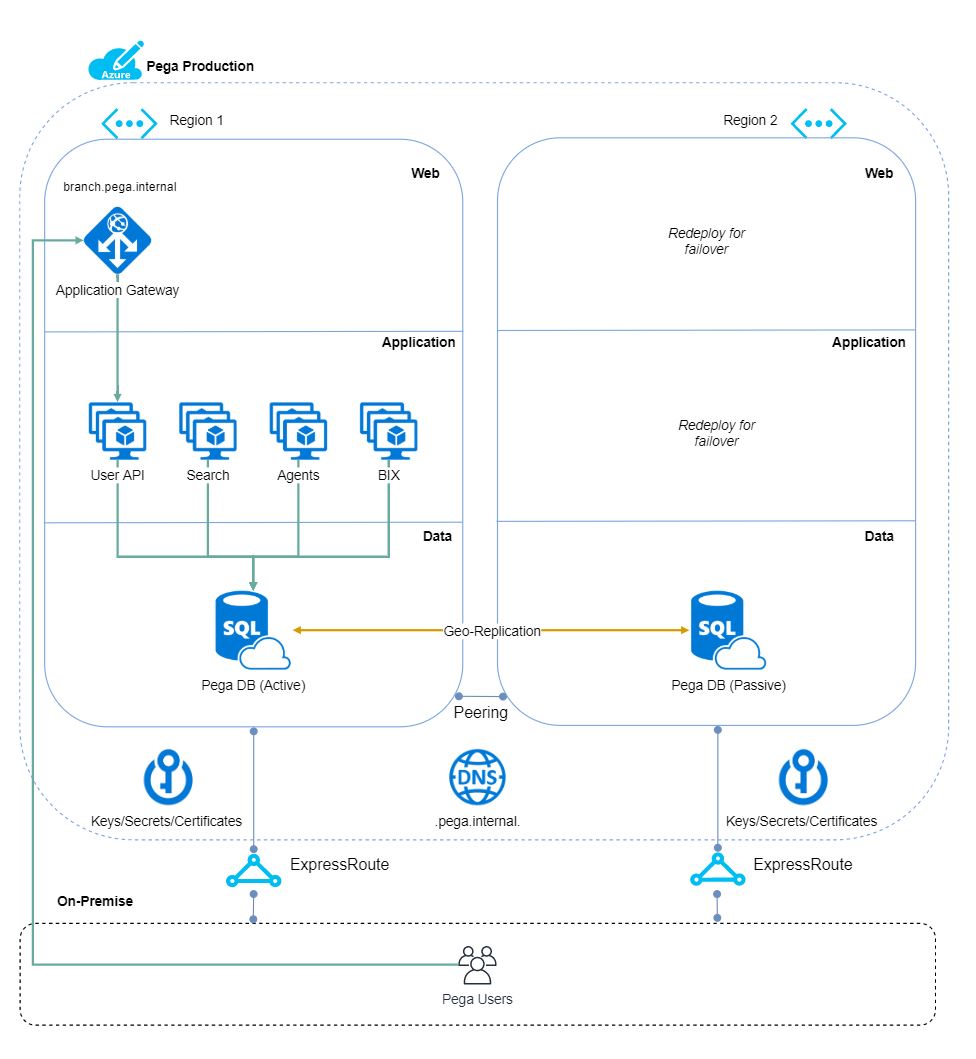
Leveraging the client’s existing automation for the deployment of Azure Resource Manager Templates, we built templates to provision the following Azure resources into Subscriptions and VNets dedicated for Pega. This solution was tiered as follows:
- Data tier: a set of SQL Managed Instances provisioned to support the Pega application data and state
- Application tier: Azure VM Scale Sets provisioned to run the Pega application on top of JBoss
- Web tier: an Azure Application Gateway for L7-aware routing of traffic to the applications running in the Scale Set
Some factors for choosing Azure SQL Managed Instance over Azure SQL Database included more complete compatibility with Microsoft SQL, greater potential storage capacity and the ability to run within an ExpressRoute connected VNet. Azure SQL Managed Instance also included Always On Availability Groups (including Auto-Failover groups to other regions) and Always Encrypted databases.
The Azure Application Gateway provided L7-aware load balancing for the solution which was a requirement to achieve session affinity. As Pega typically holds a session state on the node itself, this would ensure that users would remain connected to a single node for the duration of their session. Should that node be lost, the Application Gateway would mark it as failed and move traffic to another node, requiring the users on that node to authenticate with the application again.
The following diagram details the layout of the solution:
Deployment Philosophy
The following assumptions were critical to ensuring an elastic deployment methodology for Pega. These were:
- Core resources such as Subscriptions, VNets, and Key Vaults would be provisioned separately and follow their own life-cycle
- Application resources would come in two flavours, persistent resources and disposable resources
- Persistent resources would include items such as the database, which we wanted to preserve between deployments
- Disposable resources would include the Scale Sets running Pega — we would continuously destroy/redeploy these between deployments
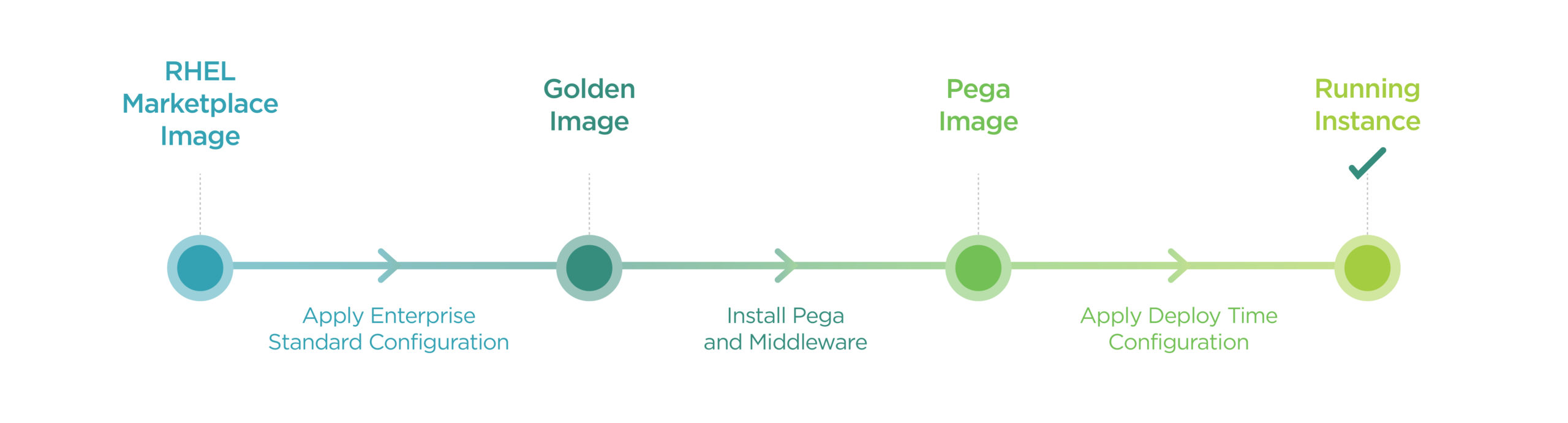
Assuming we have golden images presented to us from the platform, we are able to layer the Pega application binaries and middleware utilising a second bake methodology. That is:
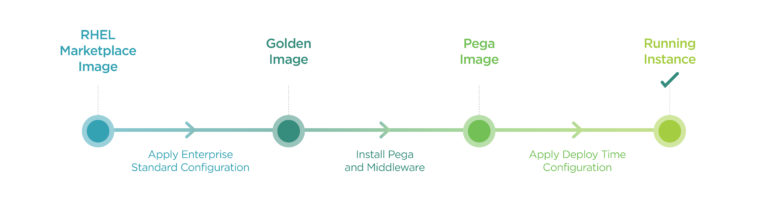
In this model, we are treating VM instances similarly to containers by layering software through images. The final deployed image then runs within a Scale Set with deployment time configuration injected. This deployment time information can include:
- Logging and monitoring configuration for OMS and Splunk
- Launch time configuration for JBoss and Pega
- Injection of secrets and certificates
Furthermore, by encapsulating the actions for each stage in Puppet Modules, and by making these Puppet Modules aware of the stage they’re operating in, we can use declarative languages to define not only the Azure resources (through Resource Manager Templates) but also the software running on the instances themselves.
This philosophy ensures that we are beginning the container journey with our client — by ensuring we’re using code and not human interaction for all components of the stack. In addition, by implementing a GitOps model for each component of the solution we are able to begin to drive operational outcomes through code change and sunset the culture of changing running configuration on instances through interactive access. This puts our client in a strong position to start their Pega 8 journey rallied around newer technology like the Azure Kubernetes Service.
The benefits of code for all components of the stack do not stop here. As we are now able to describe our environment in code, there is nothing stopping us building an arbitrary number of environments following a git branching model. Consider a model where:
- Master is always Production
- All other branches are always NonProduction
- A commit is a deployment of resources
Then we consider how to deal with our persistent resources:
- Persistent resources are created on the first commit within a branch
- Tearing down a deployment preserves persistent resources
- Persistent resources are only deleted when a branch is deleted
We’re then in a position where we can deploy Pega as follows:
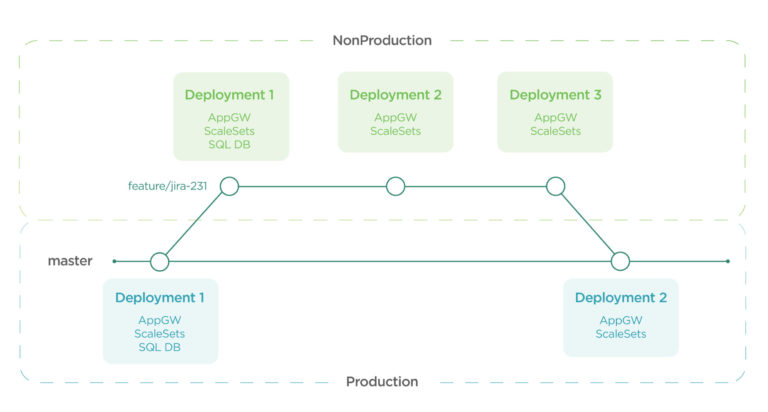
We’re now driving test environments of Pega through a GitOps model, but more importantly also controlling Production through the very same model. By carefully considering our blue/green processes, we’re able to upgrade Pega and any associated database schema changes by first testing in a feature branch, and then merging into master in a controlled manner. By making our Pega deployments themselves branch aware, we can then do nifty things like:
- Have “Branch / Build” selectors in Splunk dashboards to get a per environment view
- Inject facts from Puppet such as “branch” which will allow us to determine which environment we’re in
- Use DNS carousels on a per branch basis to make Pega deployments discoverable
Most importantly, we can now take this pattern and stamp it out repeatedly for the 50+ deployments of Pega our client has internally. This ensures a consistent deployment and operational model which should serve them well until the next iteration of the solution around Pega 8.
What’s Next?
While the solution in question is utilising VM instances for the application itself, these instances are provisioned as Scale Sets and are treated exclusively as disposable assets. This gives the instances “Pod-like attributes” and compounded with a strong philosophy of disposability, automation and GitOps lend themselves to a future where the application could more easily move towards containers and container schedulers such as Kubernetes.
It is important to consider containerisation of mission critical systems like Pega as a journey, and that simply having the application functional within Kubernetes is not sufficient as the entire operational culture around the application needs to be considered. Furthermore, Kubernetes itself requires a significant amount of platform experience, which your internal teams should be free to explore and familiarise themselves with, free from business pressures surrounding a mission critical workload.
Pega 8 has had a number of updates that put it well on the way of being a container friendly distribution of the product and we look forward to a future blog post illustrating the next iteration of this journey.
Conclusion
Over the course of the engagement, we successfully designed, built, and transitioned to Production an “at Scale” repeatable deployment of Pega on Microsoft Azure. This solution has helped our client achieve greater flexibility, reduction of cost and a step change in the way they approach technology problems in the future. This modern approach to Pega has subsequently reduced the time it took to implement new business processes from days to hours.
Additionally, the client was able to explore further optimisation opportunities such as cost reduction through auto-scaling and Azure Reserved VM Instances, allowing them to further strengthen their business case around a holistic move of Pega to the cloud.
Acknowledgements
This solution was the hard work of people within the project from both Sourced and the client. In particular, we would like to acknowledge the hard work of former Sourced team member John Rouchotas, who has moved on to new opportunities. The amount of work he put into this solution cannot be understated and is greatly appreciated.
This publication was a collaborative effort across a number of Sourced Group consultants. Sourced Group specialises in the migration and modernisation of business critical applications to the public cloud across our client base of regulated enterprises.



{kind=link}
{kind=link}