
Introduction
Secrets management in public cloud environments continues to be a challenge for many organisations as they embrace the power of programmable infrastructure and the consumption of API-based services. All too often reputable companies will feature in the news, having fallen victim to security breaches or costly cloud resource provisioning through the accidental disclosure of passwords, API tokens or private keys.
Whilst the introduction of cloud-native services such as AWS Secrets Manager or third-party solutions like HashiCorp Vault provide more effective handling for this type of data, the nature of version control systems such as git provides a unique challenge in that the contents of old commits may contain valid secrets that could still be discovered and abused.
We’ve been engaged at a customer who has a large whole-of-business ‘self-service’ cloud platform in AWS, where deployments are driven by an infrastructure as code pipeline with code stored in git repositories hosted on a Atlassian Bitbucket server. Part of my work included identifying common, unencrypted secrets in the organisation’s git repositories and provide the business units responsible a way to easily identify and remediate these exposures.
Due to client restraints in time and resourcing, we developed a solution that leveraged our existing tooling as well as appropriate community-developed utilities to quickly and efficiently meet our customer’s requirements whilst minimising operational overhead.
In this blog post, we’ll walk through the components involved in allowing us to visualise these particular security issues and work to drive them towards zero exposure across the organisation.
Understanding Bitbucket Server
As mentioned above, our client leverages an AWS deployed instance of Atlassian Bitbucket Server to store and manage their git repositories across the group.
From the application side, the Bitbucket platform contains the following data characteristics that continues to grow every day:
- 100Gb+ of git repository data
- 1300+ repositories with more than 9000 branches
- 200,000+ commits in just the master branches alone
From the AWS infrastructure side, Bitbucket server uses the following services deployed into a VPC:
| AWS Service | Function in Bitbucket server deployment |
 EC2 & Autoscale | A Linux EC2 instance to run the Bitbucket server software (Java, Elasticsearch, etc) deployed in an Autoscale group of 1 (Autoheal pattern). |
 RDS PostgreSQL | A PostgreSQL database used to store application configuration and state such as authentication configuration and pull request data. |
 EBS | An EBS volume attached to the Linux instance is used to store Bitbucket data such as the git repositories themselves as well as application and log files. |
 Elastic Load Balancer | Provides an ingress point into the application as well as application connection distribution and SSL termination. |
 | EBS Snapshots are used to regularly to provide git data backups for use in recovery and deployment scenarios. |
As part of this deployment, EBS and RDS snapshots are created on a schedule to ensure that a point-in-time backup of the application is available ensuring that the service can be redeployed in the event of a failure, or to test software upgrades to the software against production-grade data.
When these snapshots are created, a tag containing a timestamp is created that allows quick identification of the most recent backup of the service by both humans and automated processes.
Auditing git repositories
When it comes to inspecting git repositories for unwanted data, one of the challenges is that it involves inspecting every commit in every branch of every repository.
Even though the Bitbucket platform provides a search capability in the web interface, it is limited in that it can only search for certain patterns in the master branch of the repository, in files smaller than a set size. In addition to this, the search API is private and is not advocated for use for non-GUI operations, further emphasised with the fact that it returns its results in HTML format.
Another challenge that we encountered was that heavy use of the code search API resulted in impaired performance on the Bitbucket server itself.
As such, we looked to the community to see what other tools might exist to help us sift through the data and identify any issues. During our search, we identified a number of different tools, each with their own capabilities and limitations. Each of these are worthy of a mention and are detailed below:
- Git-secrets;
- Truffle Hog;
- Git Hound;
- Git-all-secrets;
- Repo-security-scanner;
- Repo-supervisor; and
- Gitleaks
After trying each of these tools out and understand their capabilities, we ended up selecting gitleaks for our use.
The primary reasons for its selection includes:
- It is an open source security scanner for git repositories, actively maintained by Zach Rice;
- Written in GO, gitleaks provides a fast individual repository scanning capability that comes with a set of pre-defined secrets identification patterns; and
- It functions by parsing the contents of a cloned copy of a git repository on the local machine, which it then uses to examine all files and commits, returning the results in a JSON output file for later use.
The below example shows the output of gitleaks being run against a sample repository called “secretsdummy” that contains an unencrypted RSA private key file.
As you can see, gitleaks detects it in a number of commits and returns the results in JSON format to the output file /tmp/secretsdummy_leaks.json for later use.
# cd /code/secretsdummy
# gitleaks --report-path=/tmp/
2018/08/27 05:57:42 fetching secretsdummy from /code/secretsdummy ...
2018/08/27 05:57:43 LEAKS DETECTED for secretsdummy!
2018/08/27 05:57:43 report for secretsdummy written to /tmp/secretsdummy_leaks.json
#
# cat /tmp/secretsdummy_leaks.json
{
"line": "-----BEGIN RSA PRIVATE KEY-----",
"commit": "13e4da5fb0377eab0a3720ae1a0350ace75a247b",
"string": "-----BEGIN RSA PRIVATE KEY-----",
"reason": "RSA",
"commitMsg": "Removing RSA Key",
"time": "2018-08-27 15:53:47 +1000",
"author": "Keiran Sweet",
"file": "id_rsa",
"repoURL": ""
}
{
"line": "-----BEGIN RSA PRIVATE KEY-----",
"commit": "c758127e1e29dbe3438048dc33ae9dc1a8cd0aa6",
"string": "-----BEGIN RSA PRIVATE KEY-----",
"reason": "RSA",
"commitMsg": "Adding a dummy RSA key for detection testing",
"time": "2018-02-19 00:03:09 +0000",
"author": "Your Name",
"file": "id_rsa",
"repoURL": ""
}
{
"line": "-----BEGIN RSA PRIVATE KEY-----",
"commit": "1c984802555a590855f2f3036e8e5065b44a3134",
"string": "-----BEGIN RSA PRIVATE KEY-----",
"reason": "RSA",
"commitMsg": "Unrelated secret",
"time": "2018-02-21 14:33:06 +1100",
"author": "Keiran Sweet",
"file": "SEKRET",
"repoURL": ""
}
#Orchestrating and Scaling gitleaks
Now that we know that gitleaks can help us identify secrets in individual git repositories and store the results in a set of JSON files, we now need to look into how we can apply this to all the repositories in the Bitbucket instance in a timely fashion.
Fortunately using the automation capabilities that AWS provides alongside the regular snapshots of the Bitbucket EBS volume, we are able to build a fast and cost effective workflow to run gitleaks across every single git repository on a nightly schedule.
To achieve this, we used the following AWS Topology, which we will walk through below, describing its execution workflow from left to right.
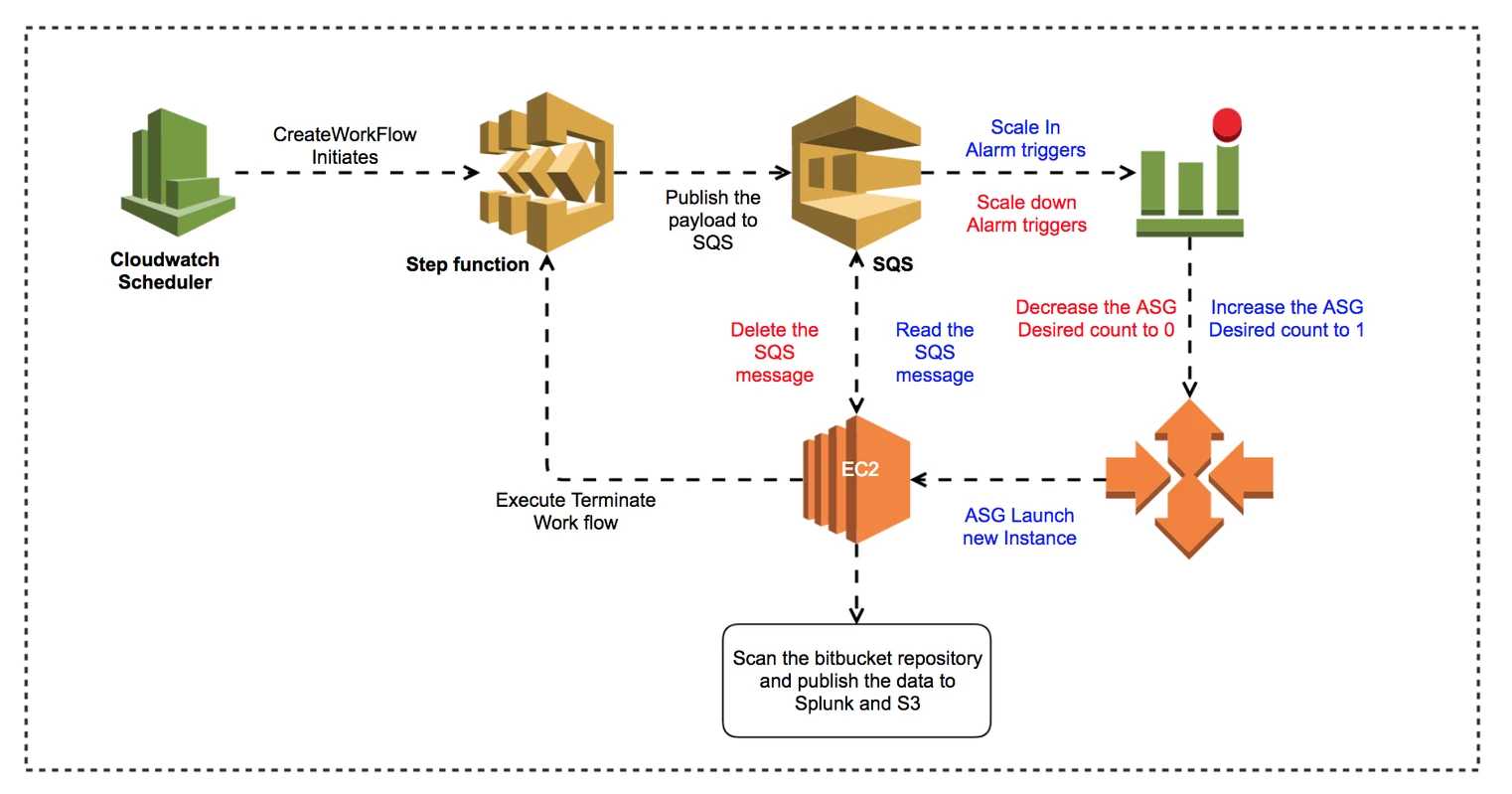
- We create a Scheduled CloudWatch Event that is responsible for triggering an AWS Step Function at a particular time of the day;
- The Step Function with some associated Lambdas is responsible for hunting for the the latest Bitbucket EBS snapshot and restoring it to an EBS volume;
- Once the EBS volume restoration has completed, a message is published to an SQS Queue that details the volume ID and other metadata, this then triggers an CloudWatch Alarm when the queue depth is greater than 0;
- The CloudWatch Alarm invokes an Autoscale scaling policy that brings an autoscaling group online with a single EC2 instance;
- When this EC2 Instance boots, it reads the message from the SQS Queue, obtaining the EBS volume IDs, attaching and mounting them on the instance EBS volumes. The 2 volumes we attach have the following function:
- The first EBS volume contains the latest Bitbucket data of which we want to audit; and
- The second EBS volume is used as temporary space which is used to store cloned repository data during the audit.
- Once the storage has been configured on the EC2 Instance, we then execute our Bitbucket auditor application, it is responsible for:
- Running a git clone operation on every git repository found on the EBS volume that contains the Bitbucket data, resulting in working copies on the scratch volume for gitleaks to operate on;
- Executing the gitleaks tool on every cloned repository in parallel batches to optimise performance;
- Consuming all the JSON report files from each gitleaks execution and building a set of consolidated reports and metrics for submission to Splunk;
- Deleting the message from the SQS queue that results in a scale-down operation on the Autoscaling group to 0 instances; and
- Unmounting the EBS volumes after execution and triggering the step function again that is responsible for deleting the EBS volumes that are no longer required.
- After the completion of the workflow the environment is in a state ready for its next invocation against the most recent EBS snapshot.
Visualising gitleaks data
As part of the execution of gitleaks across the Bitbucket repositories a large number of JSON based report files are generated.
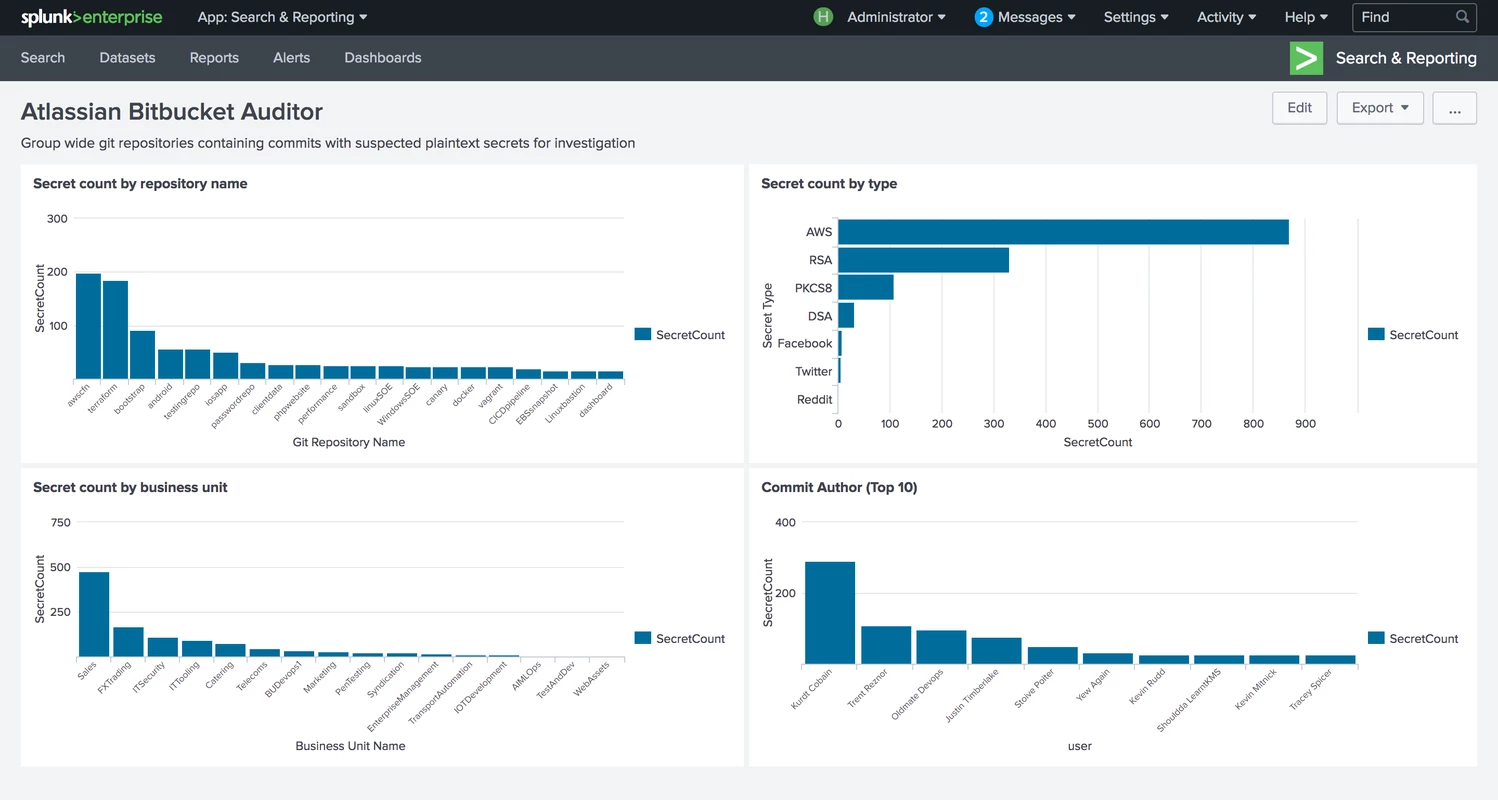
To aid in understanding the results, the auditor application consumes each of the report files and builds a larger object that contains all of the result data, allowing us to then generate a high level set of metrics about the issues that were found, such as:
- The type of secrets that are most prevalent in the environment, e.g. AWS API keys, RSA / DSA Private keys, Github keys, etc;
- The most common business units committing secrets to their code;
- The most common individual committers of secrets, this can be used to provide additional training or mentoring; and
- The most common file types containing secrets.
In addition to this, the data can then be simplified and submitted to Splunk in a way that can be visualised, giving us a detailed view similar to the following dashboard, allowing technical teams to easily identify and remediate their issues with the goal of driving potential exposures to zero.
It is important to note that we are able to re-run this report on a nightly basis, giving us the ability to have regular updates without human intervention.
Results
In building this capability we have been able to work with users in the organisation to identify and remediate a significant number of secrets that have been stored in the groups source code platform. We have also provided additional visibility into repositories where there are more opportunities for security enhancements (where there is smoke, there is fire).
Although the mechanics of secrets remediation is out of scope of this document, we encourage you to read the following documents that cover the process in great detail:
- Removing sensitive data from a repository (github.com);
- Removing sensitive files from commit history (atlassian.com); and
- Rewrite git history with the BFG (theguardian.com) – we particularly like & used this one.
Conclusions and additional musings
Although this solution resulted in significantly increased security visibility across the organisation, prevention is always better than a cure, and in addition to this capability, we also enhanced the existing CI/CD capability by adding preventative measures into the development workflow to catch potential issues before they progressed further into the environment, including:
- The advocation of using standardised .gitignore files to blacklist specific filetypes (id_rsa, *.pem, etc);
- The implementation of standardised commit hooks and CI plugins to detect problems immediately as they occur;
- Introducing a platform wide secrets management capability and educating teams on how to effectively use it; and
- Ensuring the creation of repositories is automated to ensure that, where possible, they are clearly associated with internal teams and business groups to enable effortless identification of owners. In addition to this, it also helps with building reports such as those shown above when working with raw Bitbucket data.
I’d like to acknowledge my colleagues and friends Karrup, Nick and Zach Rice who offered their expertise in delivering this solution.

Keiran Sweet is a Principal Consultant with Sourced Group and is currently based in Sydney, Australia. He works with customers to automate more and integrate with next-generation technologies.


