
Introduction
Commercial aircraft have several different communication capabilities so that the pilots and supporting staff have access to all the information they need to ensure they safely and effectively arrive at their destination. The most prevalent of these systems is the two-way air to ground data communication system called ACARS, or the Aircraft Communication and Reporting System. Deployed into most commercial aircraft since its creation in the early ’80s, it has achieved the status of being “the data-link that just works.”
Pilots in the air interact with the ground operations and air traffic controllers using a physical terminal in the cockpit. This places information at their fingertips, such as rerouting requests, clearance notifications, clearance restrictions and weather updates as well as providing on the ground engineering teams with aircraft performance data, fault notifications, position reports and so on.

ACARS functions by adhering to a strict communications protocol that has historically been a challenge when working to meet modern technology requirements such as analytics, machine-learning, and instant messaging.
To assist with these types of integrations, a third party software product called “AIRCOM: FlightMessenger” was developed by SITAONAIR to provide an interface from other systems to the ACARS platform. Using the AIRCOM product, users can define a translation model to transform the message formats between third party systems and those of the ACARS network (and vice-versa), thus providing a clean interface to extend their communication capabilities.
In this blog post, we will detail how we worked with one of our aviation clients to migrate this critical “AIRCOM: FlightMessenger” platform from their on-premises environment to AWS, aligning it with the Well-Architected Framework and providing a number of additional benefits to the business.
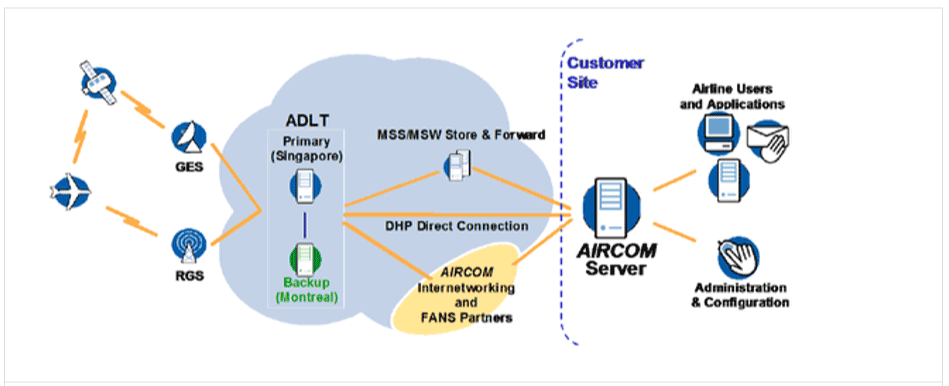
Challenges with the Existing Architecture
The original solution was hosted in a traditional data center, split across multiple geographically diverse locations and utilised technology solutions as follows:
- The application server runs on IBM Pureflex-based infrastructure in a primary data center
- The database server runs on IBM Pureflex-based infrastructure in a primary data center with asynchronous mirroring to the DR Server running in the secondary data center
- Load balancing between the web servers in the data centers was provided by an F5 Local Traffic Manager (LTM)
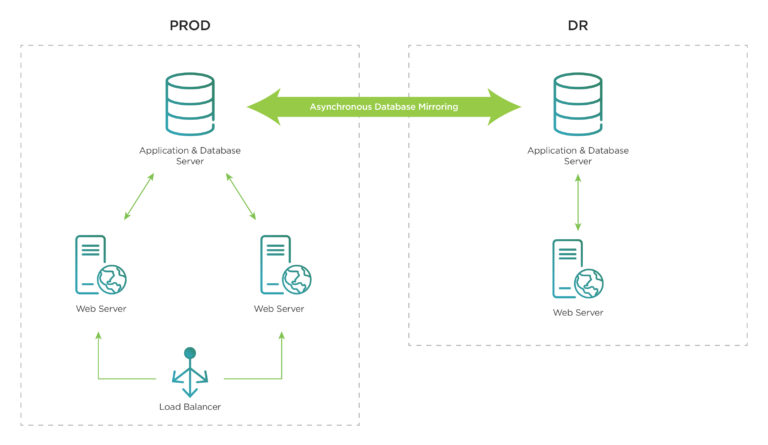
As the solution is a critical messaging interface for air to ground aircraft communications across the organisation, the number of its users and integrations grows exponentially as more aircraft, metrics and tools join the ecosystem. This growth on the existing rigid and inflexible sytem caused:
- Performance issues as an increase in transactions overwhelmed the capacity of the system, hampered by its scale-up and out capabilities limited by data center space and the lengthy procurement times
- Insufficient testing capability on the group’s single development environment to keep up with the application’s quarterly release cycle
- Extended service outages during software upgrades and infrastructure maintenance, often lasting over 2 hours
- Operational difficulties due to complex high-availability configuration and manual disaster recovery processes
To address these issues, the team made the decision to transition the system to AWS, which also aligned with the organisation’s vision of exiting their on-premise data centers over the coming years.
Discovery Taxiing
By meeting with our client’s solution architects, business stakeholders, downstream application teams and analysing the application itself, we landed on the following list of high-level requirements and characteristics our solution must have:
- Traceable – Ensure the solution is deployed with an infrastructure-as-code first approach to enable change tracking throughout its life-cycle
- Resilient – Deployments of the solution must be resilient to failures at both the infrastructure and application level with automation in place to ensure service continuity.
- Highly available – Ensure the service remains fully available in the event of a partial or full system failure
- Visible – Ensure monitoring and centralised logging solutions have coverage of all components
- Recoverable – Implement a backup and recovery system that enables the restoration of the system quickly and with minimal data loss
- Efficient – Reduce the downtime required to perform patches and upgrades of the solution
- Performant – Address the ongoing performance issues and implement the capability to increase capacity based on workload demands quickly
With this in mind, we began designing the architecture to meet the requirements.
Design Take-off
While designing the architecture, we leveraged multiple AWS services and considered best practices to achieve the design goals and customer requirements with automation and intelligence in place.
This section details how we achieved or exceeded our customer’s requirements.
Traceable
The client already had a mature CI/CD-based approach for deploying Infrastructure as Code (IaC) in AWS. Leveraging this capability allowed us to ensure that all associated infrastructure and application configuration was stored in their enterprise-grade source code repositories, ensuring the history of the solution remained transparent and traceable.
Resilient
The FlightMessenger application is a traditional Commercial Off-The-Shelf (COTS) application running on Windows Server. It is comprised of multiple services and is tightly coupled with Microsoft Messaging Queue (MSMQ). With MSMQ’s default behavior of discarding all transactions in the queue during a restart, the operations team was forced to manage any scheduled maintenance of the server by failing over to the disaster site.
We needed to ensure that in our solution, this type of manual intervention would no longer be required and that the application was sufficiently resilient to failures. We were able to achieve this using the following techniques:
- With the client’s IaC Pipeline, we baked the application installation and its dependencies into an Amazon Machine Image (AMI), providing us with the ability to launch a fully functional, immutable EC2 instance.
- Using this AMI, we deployed the EC2 Instances into the environment using an “Auto Heal Pattern“. The Auto Heal Pattern comprised of an Auto Scaling Group with a maximum, a minimum and a desired size of one as well as Persistent EBS volumes and Elastic Network Interfaces (ENIs) to ensure application availability in the event of an instance failure or termination.
- Using these capabilities, alongside the relocation of the MSMQ queue data to a persistent EBS volume, we were able to ensure that there were zero messages lost in the event of an instance failure/termination event.
- To provide an additional level of durability, regularly syncing the MSMQ datastore to S3 allowed us to retain messages in the event of an Availability Zone (AZ) failure.
Highly Available and Redundant
In the existing solution, the application and database services shared the same compute infrastructure. For the new solution, we split these out onto their own instances with the following configuration to increase resiliency against failures.
FlightMessenger Database Tier
FlightMessenger uses Microsoft SQL Server (MSSQL) as a database. Although MSSQL is an available engine type in AWS RDS, the software vendor had not yet certified RDS and would not provide support if we utilised it. As such, we were unable to use it in our solution.
Instead, we deployed a highly-available configuration of MSSQL on EC2 instances backed with persistent EBS volumes across two AZ’s, with replication enabled.
Failover between AZ’s was achieved through a combination of Route53 routing policies and CloudWatch Metrics.
FlightMessenger Application Tier
Similar to the database tier, we deployed the application on EC2 instances. These EC2 instances were backed with persistent EBS volumes deployed across two AZs and had associated static IPs with each of the hosts via ENIs. The application runs in an “Active – Hot Standby” mode using Windows Task Scheduler to provide application service discovery and availability in place for detective auto-failover.
For the disaster recovery site, the client maintained a standby environment which could be brought online in the event of a catastrophic failure of the primary. However, engaging this process is operationally costly as there is a risk of losing messages.
Visible
We integrated our solution with the client’s existing Splunk infrastructure as it was their enterprise solution for monitoring and alerting.
Splunk Universal Forwarders were installed on each instance and configured to push logs to Splunk Heavy Forwarders and subsequently Indexers.
Splunk Dashboards were then built that allowed the client to:
- Have operational insights to check the health of aircraft communications
- Have scheduled report generation
- Monitor for any progressive improvements, server health and fault detection
- Integrate with ServiceNow for alerting & incident management
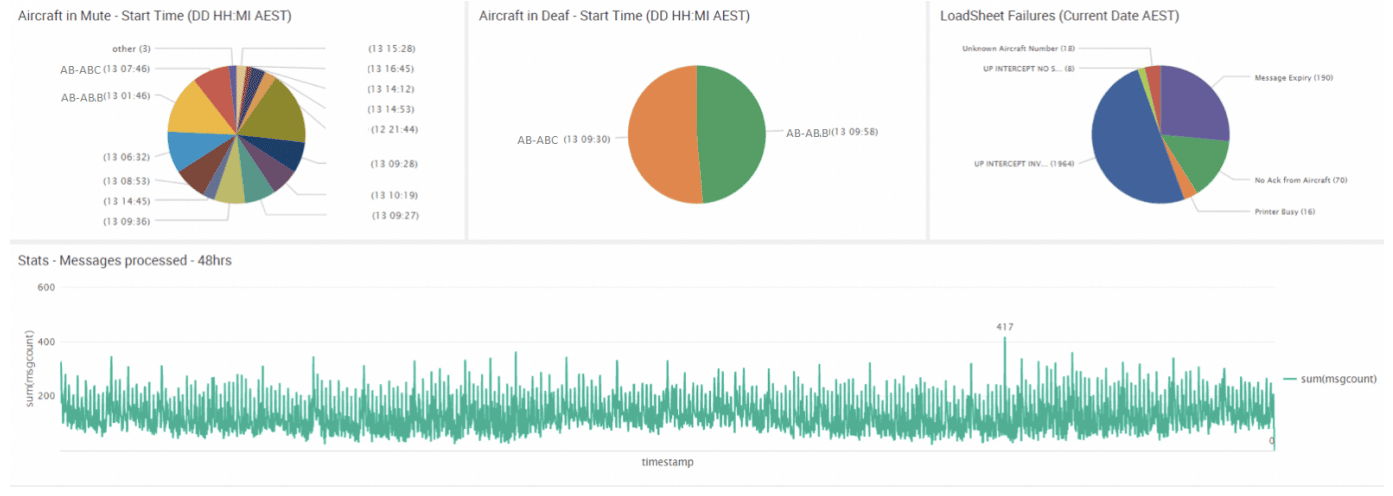
Performance
Performance issues were one of the key driving factors for our client to move to the cloud.
Through replaying multiple iterations of message payloads into the application, monitoring application behaviour and rate of message processing stats using Splunk and leveraging Datadog for infrastructure metrics, we were able to select the right instance types resulting in 150% efficiency compared to the original on-premises systems.
Backup & Recovery
AIRCOM: FlightMessenger predominantly requires two data types to be backed-up for recovery.
Non-Processed MSMQ queued messages
To achieve this, the MSMQ messages are synced to S3 for standby instance to download in case of failover events.
SQL Database data and log files
To achieve this, we:
- Created backups files using Native SQL Server Jobs and periodically synced them to S3 for archiving and recovery
- Used the client’s in-house backup solution to create EBS volume snapshots of the data volumes and used its life-cycle functionality to remove them when they are no longer required
Disaster Recovery
In the existing environment, the client used to perform a manual failover which is operationally costly for airline operations given the criticality of the application.
As part of the new solution, we were able to automate the disaster recovery process by implementing a detective auto-failover mechanism. This is achieved by building a custom health detection and auto-failover job which are run at regular intervals in the Windows Task Scheduler. This job, which runs on each of the application instances, determines its own state and health of its pair instance running in an alternate AZ.
Using application-aware intelligence that is embedded within the job, it has the ability to automatically change the instance state from active to standby mode and vice-versa when failure scenarios are detected.
Simplified Application Upgrades
As the entire application stance is provisioned end-to-end through code, combined with a deeper understanding of CI/CD principals, we were able to help our client in reducing application upgrade times from the typical 2 hours to less than an hour alongside reducing the rollback window from 30 minutes to sub 15 minutes.
The Architecture Cruise
To understand how the architecture looks and to visualise how messages route from the aircraft through to AWS hosted applications, you can see an example application topology below:
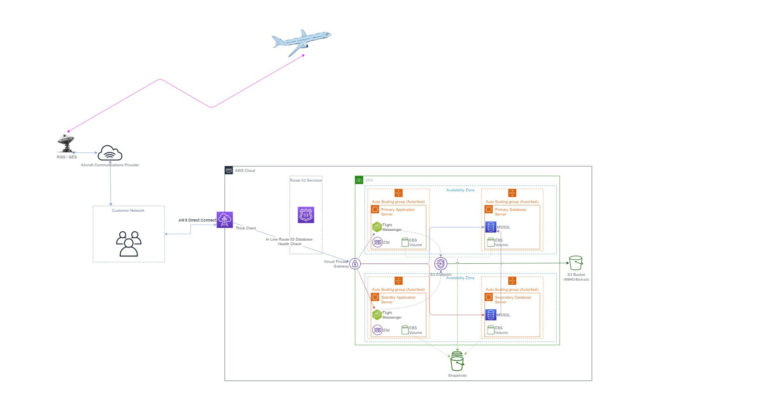
As part of the architecture, we also had a goal to align with the AWS Well-Architected Framework. In the table below, you can see the technologies, techniques and services we introduced to align with each of the pillars.
| AWS Well Architected Pillar | Tools / Technology / Services Used |
| Operational Excellence | Splunk for application health insights Datadog for AWS Infrastructure health and insights Atlassian Bitbucket and Bamboo for infrastructure as code and automation tasks ServiceNow for incident tracking and escalation |
| Security | Core AWS services such as KMS / IAM / Cloudtrail to provide foundational security capability Splunk for application and instance security event correlation |
| Reliability | Auto scaling and auto healing for instance resiliency EBS Snapshots and data offload to S3 for backup and recovery ELB and Route53 healthchecks for service availability and automated service failover CloudWatch, Splunk and Datadog alarms & alerts for notification of application issues |
| Performance & Efficiency | Splunk for application performance insights Datadog for AWS Infrastructure performance insights EC2 Instance and Storage right sizing based off real time performance data |
| Cost Optimisation | EC2 Instance and Storage right sizing based off real time performance data Solution cost observation based on Cloudability insights |
Landing into Production
AIRCOM: FlightMessenger, being a highly critical application, required the same vigilance in planning the migration procedure as the technical design.
The entire migration process was automated to ensure zero-manual errors during the cut-over to production. The migration team then rehearsed the process multiple times to ensure all members were familiar with the expected procedure and to identify any problem areas of the plan.
The flowchart below describes the final migration process.
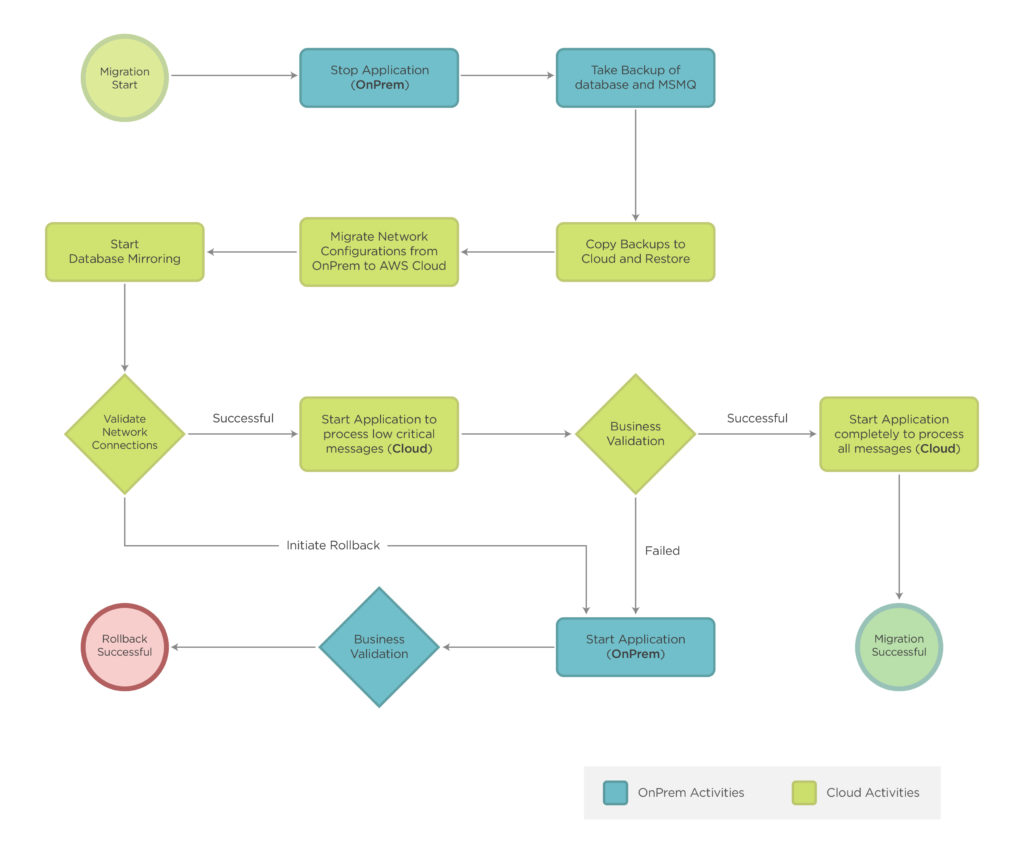
Client Outcomes
As a result of the successful migration of our client’s AIRCOM: FlightMessenger from the legacy on-prem hosting to AWS infrastructure, our client realised several vital outcomes.
- The service could now handle a full AZ outage with failover complete in approximately 20 minutes
- Individual services auto heal within 12 minutes
- The downtime required to perform an application upgrade decreased by 50%
- Message processing capacity increased by 150%
- Business insights and configuration drift alerts from the application data are available through Splunk dashboards
- Infrastructure-as-code, version control, and CI/CD deployments provide configuration documentation, consistency, and traceability of all AWS infrastructure
These outcomes will ensure our client’s continued success in providing critical analytics, insights, and support of their growing air-to-ground data streams.
Appendix
- ACARS – Aircraft Communications Addressing and Reporting System
- Sitaonair – Aircom Flight Messenger
- Microsoft Message Queuing (MSMQ)
- The AWS Auto Heal Pattern
- AWS Well Architected Framework
- Image Credit – Spectralux

Sarat Nulu is a Consultant at Sourced Group specialising in AWS. He has a passion for leveraging DevOps and CI/CD principles to migrate complex and highly material applications to the cloud.



{kind=link}