Introduction
Recently we have been fortunate to work with one of our enterprise clients on the development and launch of a mission critical system running on AWS. The system carries the highest criticality rating for the enterprise, requiring complete deployment automation using their existing AWS deployment pipeline, whilst maintaining the highest levels of availability and reliability.
One of the more challenging requirements of the engagement was to deploy a highly available database running Oracle 12c. In this post we will be discussing how we achieved this by deploying Oracle RDBMS on EC2, using a combination of Oracle Data Guard and HashiCorp Consul, while outlining some of the challenges we encountered during this project.
Why not AWS RDS?
In most cases, the platform selection for Oracle database on AWS would lead towards the use of the RDS Platform as a Service with its:
- High performance– fast and predictable with push button scaling;
- High availability and reliability– simple, automated backup and recovery capabilities including Multi-AZ deployments and automated snapshots; and
- Automation capabilities– automated patching and database event notification without human interaction.
Unfortunately this particular application required a number of Oracle RDBMS features that were not available with the AWS RDS. Specifically the application stack required two features – Oracle Spatial and Java stored procedures, that were not available with AWS RDS when we commenced the project. Additionally, the software vendor had also not certified their product for use with RDS, leaving us with the challenge of deploying and managing our own highly available Oracle capability.
Note: Please note that at the time of writing this article, Oracle Spatial was not available (but now is) and supported on RDS.
Challenges with running Oracle on EC2
Although there are a number of documents and white papers that detail Advanced Architectures for running Oracle RDBMS in AWS, one of the biggest challenges that we faced was with the deployment automation and management of a tightly coupled and highly stateful database application, whilst observing the client’s desire to leverage auto-healing and blue/green release methodology. To achieve the desired outcome, we needed to introduce additional technologies to assist with managing the lifecycle of an Oracle database running on EC2.
Introduction to HashiCorp Consul
HashiCorp Consul is a highly available and distributed service discovery and KV store service.
To quote the HashiCorp website:
Instead of load balancers, connectivity in dynamic infrastructure is best solved with service discovery. Service discovery uses a registry to keep a real-time list of services, their location, and their health. Services query the registry to discover the location of upstream services and then connect directly. This allows services to scale up/down and gracefully handle failure without a load balancer intermediary.
In this particular environment, a Consul server cluster is deployed as a three node cluster and although this component of the solution is out of scope for this article, you can find more information about how to do this yourself on HashiCorp’s Bootstrapping a Datacenter page.
Each client connecting to the Consul server cluster requires the Consul client to be installed, fortunately HashiCorp has simplified this process by providing a single binary that:
- Provides both server & client capabilities;
- Runs as a service; and
- Is available for wide range of platforms and operating systems.
Consul uses an agent-based model in which each node in the cluster runs as a Consul client. This client maintains a local cache that is regularly updated from the cluster servers and can also respond to queries by other nodes in the cluster; this allows Consul to do connection enforcement at the edge without always communicating to the central servers.
Within Consul itself, the configuration data is stored as an hierarchical key/value store, and based on events that occur on the clients, consul is able to distribute changes to other client nodes in the cluster enabling the rapid distribution of configuration updates.
To enable these changes to occur on the nodes, and within the applications that are running on them, the following Consul capabilities are used in this solution;
- Consul Templates – Consul Templates provide a convenient way to populate values from Consul into configuration files on the node; and
- Consul Watches – Consul Watches use queries to monitor the state of values within Consul for any configuration or health status updates and then invoke user specified scripts to handle the changes and reconfigure the nodes or hosted applications accordingly.
Using these two components of Consul, we are able to easily build reactive infrastructure that can dynamically reconfigure itself ensuring the health of a running application.
In the next section, we will demonstrate how this has been used to provide a highly available Oracle capability on EC2.
Using HashiCorp Consul to achieve high-availability for Oracle Database
To achieve a highly-available solution for Oracle Database, we required the following:
- Configured and enabled Oracle replication between two nodes, leveraging a fast network interconnect to ensure that there is no lag leading to data loss caused by a node failure;
- Oracle Data Guard observer needs to be running to ensure that the primary node’s database is in sync with the standby node. This functions by connecting to the standby database node and ensuring that replication and heartbeats are occurring from the primary node. The observer is configured externally to the database nodes. In this particular environment we have configured this role to be running on the consul leader; and
- A monitoring and orchestration capability that can execute commands on the Oracle nodes in the event of a failure to ensure that reconfiguration and promotion tasks are performed, such as when the primary node becomes unavailable.
When designing the solution, we also needed to factor in the following constraints within the client’s environment:
- AWS Load Balancers– Given the nature of Oracle in this particular environment, specifically in its use of regular long running queries (> 60 minutes), it was not possible to front the database with an ELB because of the maximum timeout period of 1 hour for TCP connections. Doing so would affect the result in connection termination and query failure; and
- DNS– The client’s approach to DNS records management and governance, prevented us from updating the records programmatically and carried some risk of the records becoming stale or unresolved during a network isolation event.
Fortunately, Consul’s service discovery and other capabilities were able to help us overcome these issues with the following design and implementation.
Technical Implementation
The following sections detail our technical implementation of the eventual solution with a high-level architecture diagram and detailed descriptions of how the solution is deployed using our client’s deployment pipeline.
High Level Architecture
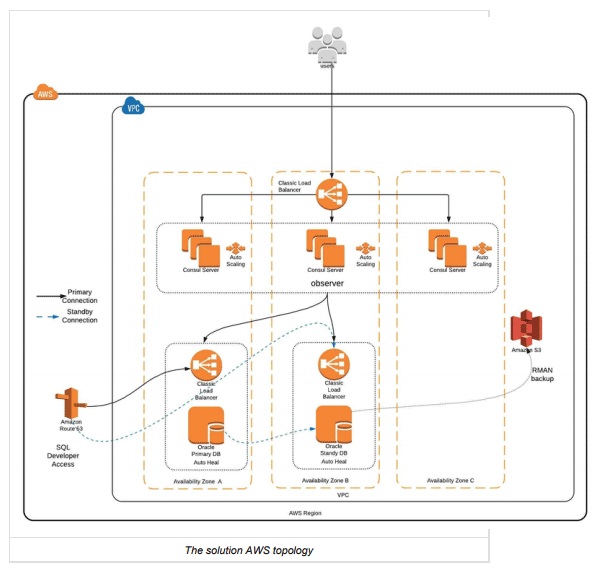
Bake Phase
During the bake phase of the deployment, we take the client’s latest Linux Standard Operating Environment (SOE) and and make the following changes to it prior to baking it into another AMI for use in the deploy phase:
- Install the Oracle 12c binaries alongside any one-off patches to the software;
- Configure the Oracle environment using a configuration management tool to apply any configuration settings required for running the database, such as:
- User account creation;
- OS system limits and kernel settings;
- Filesystem permissions; and
- Global Oracle application configuration settings.
- Ensure that the database is configured not to start automatically on launch.
Once completed, the AMI is then baked, where it will be used in the deploy phase to launch EC2 instances that run the Oracle database itself.
Deploy Phase
Now that AMIs have been created that contain all the Oracle application dependancies, using the client’s AWS pipeline, the following actions are performed:
- Two EC2 instances are launched in different availability zones (AZ’s) using the autoheal pattern. During this launch, EBS volumes are attached to the instance that contain the Oracle data; and
- During the instance bootstrap, the following actions are executed on each instance:
- The Oracle filesystems on the attached EBS volumes are mounted;
- The instance bootstrap is executed using cfninit / cloudinit;
- Consul is installed and started on the instance in client mode to discover other nodes and values for the environment;
- Consul queries the cluster and using a Consul template it updates the /etc/hosts file to provide local name resolution of the other Oracle nodes in the cluster;
- The Oracle configuration is updated with relevant Oracle node configuration, such as in those required in tnsnames.ora and listener.ora;
- The database is started in a mount state where it will determine the state it is in prior to going offline;
- It will use the Consul CLI to issue a consul kv get primarydbcommand to determine the state of the other database node:
- If other database node has already transitioned to primary then it will execute a script to convert the current database to physical standby; or
- If other database is not the primary then the database is opened for read / write operations, and the secondary will become the standby and automatically commence replication.
- Once the nodes are online, consul health checks will be performed every minute to update database role in KV store; and
- The database platform is then online for use.
Database failover scenario
With the application now deployed, we can now examine failure scenarios. For example, when considering an Availability Zone or EC2 instance failure affecting the primary node, the following Consult orchestrated actions will occur, returning the database to service automatically on the secondary node:
- Failure occurs resulting in the termination of the EC2 instance running the database primary
- The Data Guard observer that is running on the Consul leader times out after 90 seconds, indicating an instance or application failure.
- The Data Guard observer automatically promotes the standby database to the primary role
- Consul health checks running on the database nodes updates the KV store with the new database role (specifically primarydb or standbydb)
- Consul watchers on other nodes update configuration with the new database IP addresses for connectivity
At this stage, the database is now back online and in service for queries.
When the former primary instance is replaced with a new instance, the bootstrap scripts checks to see if there is currently an active primary database online, and executes scripts to become the physical standby, as the Data Guard service commences observing.
This brings the database capability back into an Active/Standby configuration again in which it is resilient against failures
Dynamic configuration of application servers with Consul
The other system component that require orchestration are the application servers themselves. The application servers are deployed as a set of JBoss application servers deployed in an Auto Scaling group attached to an Elastic Load Balancer (ELB). The ELB is configured to have a health check to a JBoss application URL that returns 200 when there is an online connection to the database.
In the event of a database failover, the following actions occur to return the application to service:
- JBoss ELB health checks fail, indicating a database connection failure;
- As ELB health checks are being used, the EC2 instances are terminated and replaced; and
- During launch, the replacement EC2 Instances execute a bootstrap script that queries Consul for the current primary & standby database addresses and populates the /etc/hosts file using Consul templates, allowing the application to return to service.
Application recovery has been achieved through complete automation without any human intervention.
The code sample below shows how the /etc/hosts file can be populated with database addresses using a consul template to direct the application to the currently active database server.
Application Host file
# consul-template generated
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
<%= @ipaddress %> <%= @fqdn %>
# hosts by nodes
{{range nodes}}{{with node
.Node}}{{.Node.Address}} {{.Node.Node}}{{end}}
{{end}}
# Primary DB addr
{{$primarydb := key
"DB/primarydb"}}{{$standbydb := key
"DB/standbydb"}}
{{ if eq $standbydb "PRIMARY-READWRITE"
}}{{with node "standby" }}{{.Node.Address}}
fpadb{{end}}{{end}}
{{ if eq $primarydb "PRIMARY-READWRITE"
}}{{with node "primarydb" }}{{.Node.Address}}
fpadb{{end}}{{end}}Additional configuration components
As part of this solution, the following components were also put in place to provide a robust and easy to use capability.
Flash recovery and regular backups
To provide a capability to rewind the database rapidly to a point-in-time, Flash recovery has been enabled, and to ensure that the platform could meet the RTO/RPO objectives, RMAN backups are configured on both database nodes, with the backup data regularly copied to S3. This provides a capability to recover the database in the event of a catastrophic failure of both nodes, in the event of data corruption or for seeding the non-production environments.
Elastic Load Balancers (ELBs)
To provide the database team a consistent interface to each of the nodes for database administration tasks, as well as endpoints for Data Guard observer connectivity, ELBs have been put in place in front of each node.
Conclusion
The automation and management of tightly coupled and highly stateful applications in cloud environments whilst meeting mission critical RTO/RPO objectives can be a difficult task. By utilising HashiCorp Consul to assist in the configuration and management of Oracle RDBMS on EC2, we were able to ensure that we delivered a highly available, resilient business critical system on AWS, whilst still maintaining application recovery without human intervention.
Appendix
- HashiCorp Consul
- Consul Templates
- Oracle Spatial
- Oracle Spatial on RDS
- Oracle Database on AWS(Architecture)
- Oracle Flash recovery
- Getting started with Oracle RMAN
- Introduction to Oracle Data Guard
- The AWS Autoheal Pattern

Vasanth Selvaraj is a consultant with Sourced Group and is currently based in Sydney, Australia. He specialises in delivering secure, scalable, and cost effective cloud solutions.


